Оглавление
Команда PyTorch представила метод, который значительно повышает эффективность вывода языковых моделей при работе с последовательностями переменной длины. Речь идет о Nested Jagged Tensors (NJT) — специализированной структуре данных, позволяющей избежать затратных операций паддинга.
Проблема паддинга в языковых моделях
Современные модели на основе LLM, такие как DRAMA от Facebook*, демонстрируют впечатляющие результаты в тестах, но их промышленное внедрение сдерживается высокими вычислительными затратами. Основная проблема — необходимость дополнения последовательностей до одинаковой длины (паддинг), что приводит к бесполезным вычислениям на pad-токенах.
Решение: Nested Jagged Tensors
NJT — это специализированный формат тензоров в PyTorch, предназначенный для работы с «рваными» данными переменной длины. В отличие от обычных тензоров, требующих паддинга, NJT хранит данные в упакованном непрерывном блоке памяти, исключая вычисления на пустых токенах.
Ключевые преимущества NJT:
- Экономия памяти за счет исключения pad-токенов
- Снижение вычислительной нагрузки на 40-60%
- Поддержка батчей с сильно различающимися длинами последовательностей
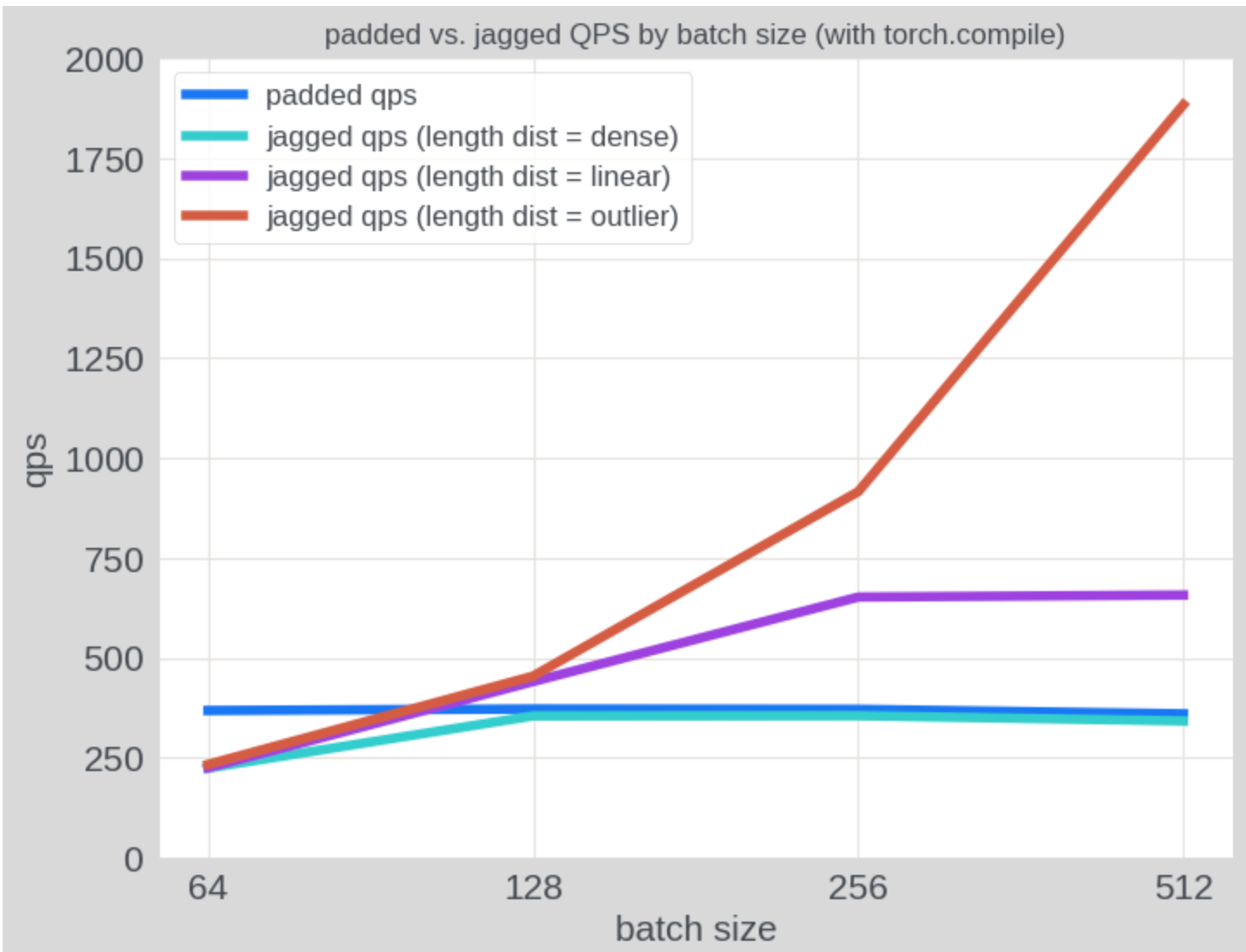
Результаты тестирования
На синтетических данных с тремя типами распределений длин последовательностей NJT показал:
- 1.7x ускорение на линейном распределении
- 2.3x ускорение на данных с outliers
- Постоянную стоимость вычислений в отличие от паддинга
Техническая реализация
Для адаптации модели DRAMA под NJT потребовались изменения в двух ключевых компонентах:
Преобразование входных данных
jagged_input_ids = torch.nested.nested_tensor( tokenizer_output.input_ids, layout=torch.jagged ) attention_mask = None
Адаптация механизма внимания
Были реализованы отдельные функции для работы с jagged и dense тензорами в Grouped Query Attention и Rotary Position Embedding:
def repeat_jagged_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: batch, num_key_value_heads, slen, head_dim = hidden_states.shape expand_shape = (batch, num_key_value_heads, -1, n_rep, head_dim) if n_rep == 1: return hidden_states hidden_states = ( hidden_states.unsqueeze(3) .expand(expand_shape) .transpose(1, 2) .flatten(2, 3) .transpose(1, 2) ) return hidden_states
Этот подход кардинально меняет экономику развертывания языковых моделей в продакшене. Технология особенно ценна для задач поиска и ретривера, где длины запросов и документов сильно варьируются. Вместо покупки дополнительного железа можно получить почти двукратный прирост производительности программными методами.
Практические рекомендации
Разработчикам стоит учитывать, что NJT имеют завышенную стоимость на малых размерах входных данных из-за реализации на Python. Рекомендуется компилировать NJT-операции для устранения этой нагрузки и получения дополнительного ускорения за счет слияния операций.
По материалам PyTorch Blog
* принадлежит Meta (признана экстремистской и запрещена в РФ)





Оставить комментарий