Оглавление
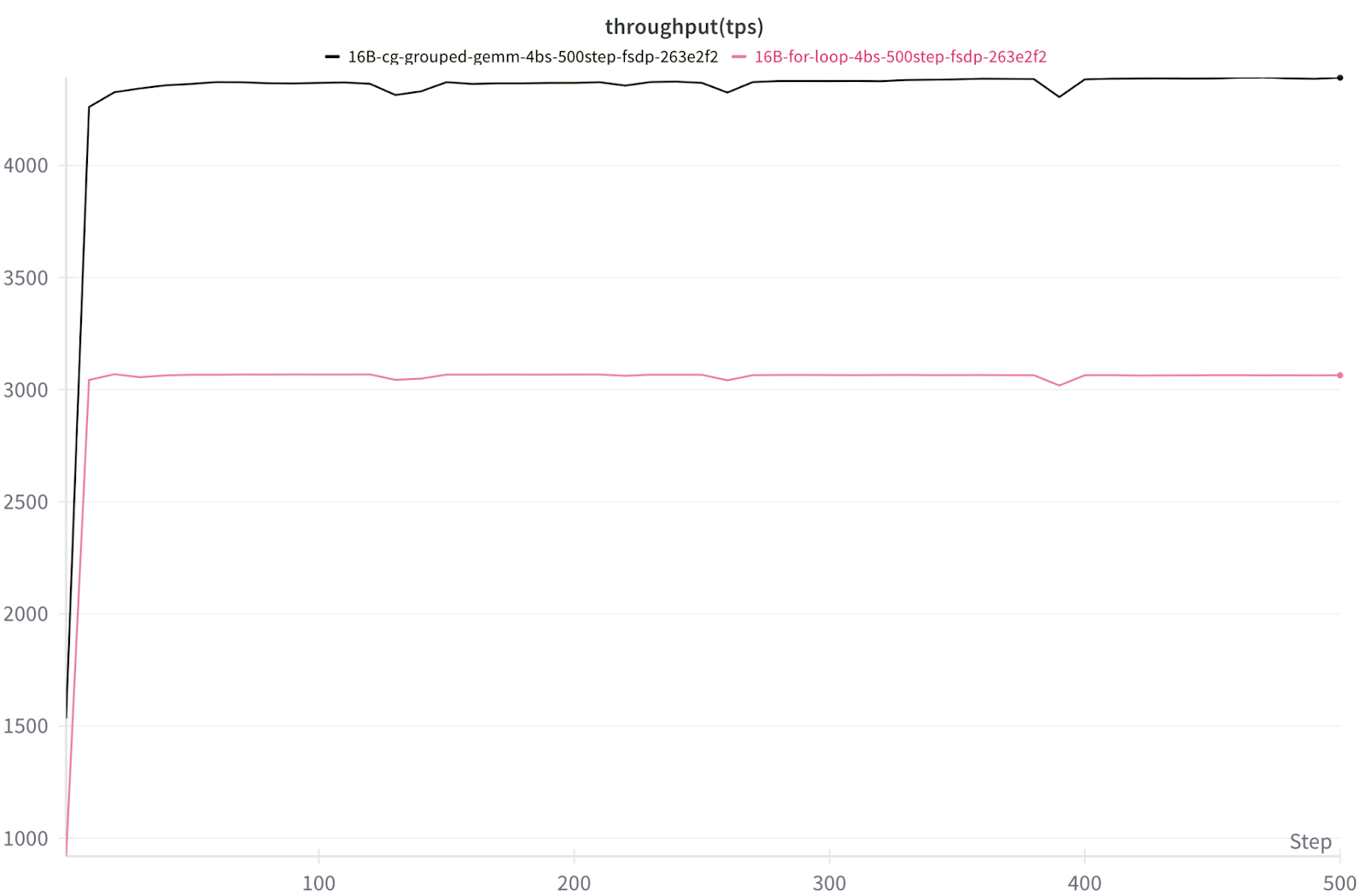
Разработчики PyTorch представили оптимизированное ядро Triton для операций Grouped GEMM, обеспечивающее до 2.62x ускорение при обучении MoE-моделей (Mixture-of-Experts) типа DeepSeekv3 на GPU NVIDIA H100. Вместо последовательного выполнения матричных операций в циклах, новый подход объединяет их в пакетные вычисления с тремя ключевыми оптимизациями.
Технические инновации
Grouped GEMM выполняет несколько независимых матричных умножений за одну запуск ядра, что критично для MoE-архитектур, где токены динамически распределяются между экспертами. Базовая реализация на PyTorch требует цикла с последовательными запусками ядер, создавая накладные расходы.
Три оптимизации производительности
Persistent Kernel Design
Вместо запуска отдельного threadblock для каждой операции, ядро использует фиксированное количество вычислительных блоков (по числу SM-модулей GPU), которые динамически получают задачи. Это устраняет волновую квантизацию (wave quantization) и повышает утилизацию ресурсов.
Групповая организация вычислений
Изменение порядка обработки матриц с row-major на grouped launch улучшает локальность данных. Эксперименты показывают рост попаданий в L2-кэш на 60% и ускорение на 1.33x за счет повторного использования фрагментов матриц экспертов.
Использование Tensor Memory Accelerator
Аппаратный блок TMA в GPU Hopper загружает веса экспертов напрямую в shared memory, освобождая вычислительные ядра. Динамическое создание TMA-дескрипторов для произвольных экспертов решает проблему runtime-роутинга в MoE.
Это не просто теоретическое улучшение — при тестировании на кластере из 8x H100 с FSDP2 скорость обработки DeepSeekv3 выросла в 1.42-2.62 раза. Для инженеров, работающих с гигантскими MoE-моделями, такие низкоуровневые оптимизации становятся критичными: они превращают дорогостоящие GPU из «прожорливых калькуляторов» в эффективные инструменты. Ирония в том, что прорыв достигается не новыми алгоритмами, а грамотным использованием железа через Triton — словно гонщик Formula 1, вдруг обнаруживший скрытую шестую передачу.
По информации PyTorch Blog.





Оставить комментарий