
Оглавление
Инженеры Meta* представили детальный разбор методов сокращения времени компиляции в PyTorch 2.0 для внутренних рабочих нагрузок компании. Речь идет о фундаментальных моделях рекомендательных систем, где начальная компиляция могла занимать более часа.
Проблема компиляции в крупномасштабных моделях
PyTorch 2.0 принес революционные улучшения в скорости выполнения моделей, но ценой этого стала значительная задержка на этапе компиляции. Для сложных архитектур, выходящих за рамки стандартных трансформеров, это превращалось в серьезное узкое место.
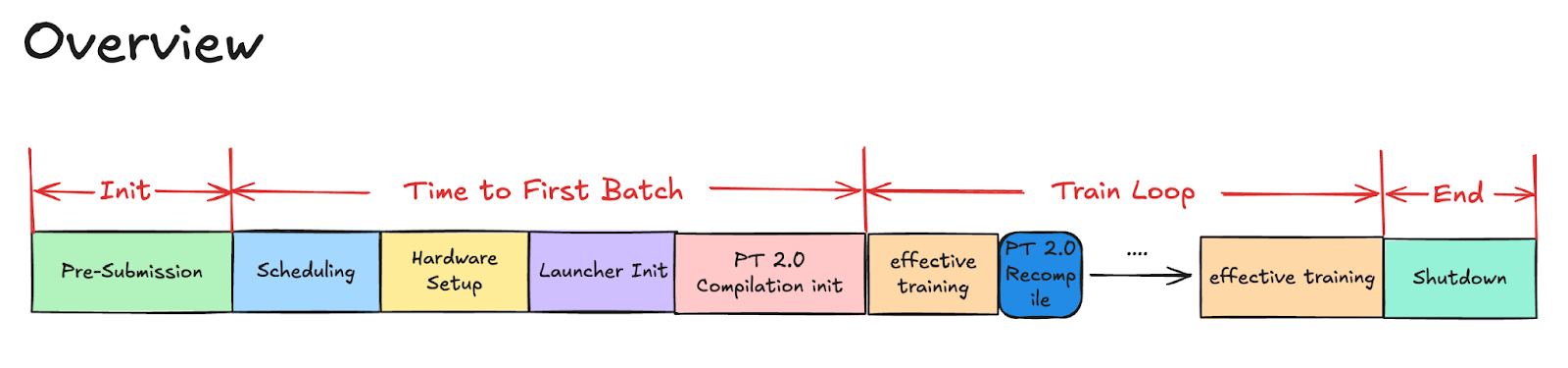
Анализ bottlenecks с помощью Tlparse
Команда использовала инструмент Tlparse для детального анализа процесса компиляции. Этот инструмент парсит логи torch trace и выводит HTML-файлы с анализом данных, позволяя идентифицировать узкие места на различных этапах компиляции.
Запуск осуществляется через установку переменной окружения:
TORCH_TRACE=/tmp/my_traced_log_dir example.py
Затем данные передаются в tlparse:
tlparse /tmp/my_traced_log_dir -o tl_out/
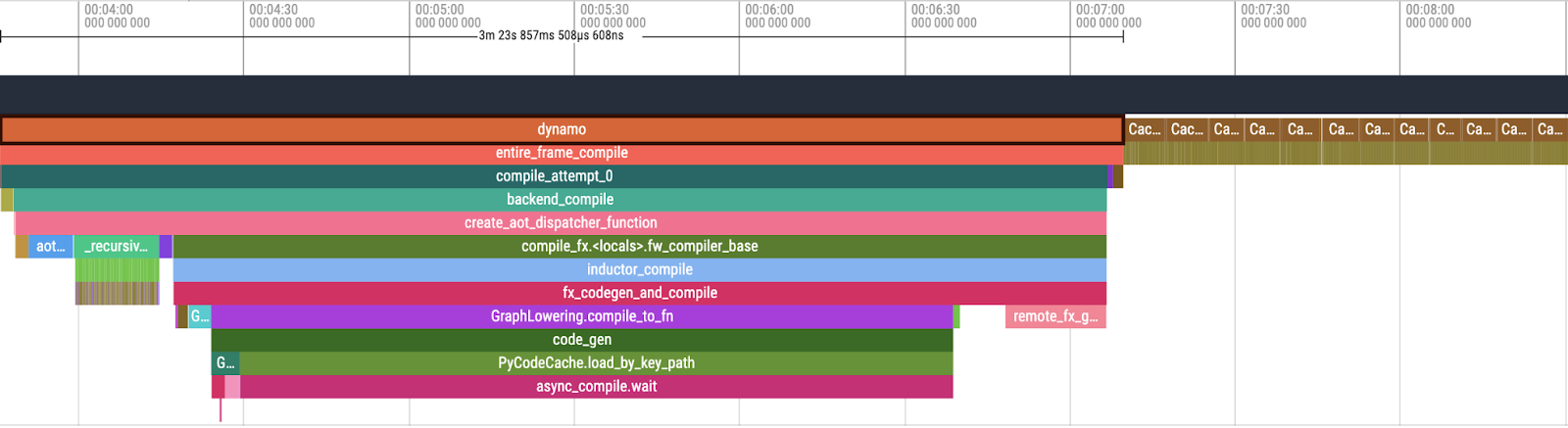
Ключевые компоненты компиляционного стека
Анализ выявил три основных компонента, влияющих на время компиляции:
- Dynamo: начальная стадия динамических преобразований графов
- AOTInductor: трассировка autodiff для генерации backward traces
- TorchInductor: компилятор глубокого обучения, генерирующий код для различных акселераторов
Распределение времени компиляции
Исследование показало следующее распределение времени:
| Фаза | Время (секунды) |
|---|---|
| Общее время | 1825.58 |
| Dynamo | 100.64 (5.5%) |
| AOTDispatch | 248.03 (13.5%) |
| TorchInductor | 1238.50 (67.8%) |
| CachingAutotuner | 238.00 (13.0%) |
Пять ключевых методов оптимизации
1. Максимизация параллелизма Triton компиляции
Оптимизация включает избегание Triton компиляции в родительском процессе и более ранний запуск компиляции в worker-процессах. Это увеличивает параллелизм и сокращает общее время компиляции.
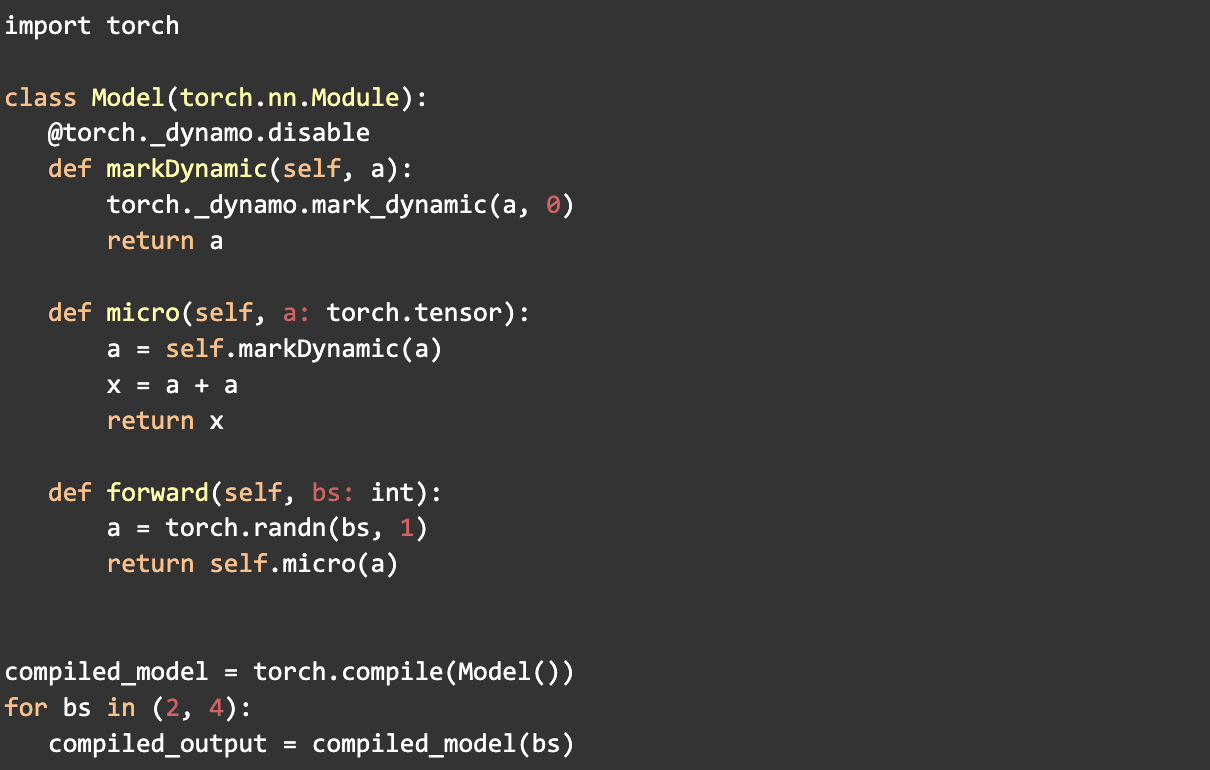
2. Динамическая маркировка форм
Использование API mark_dynamic помогает идентифицировать динамические формы до компиляции. Многие перекомпиляции происходят из-за изменений форм тензоров, поэтому маркировка этих форм как динамических значительно сокращает количество перекомпиляций.
3. Улучшение кэширования
Профильная оптимизация (PGO) могла нарушать кэширование, приводя к недетерминированным ключам кэша. Решение включало реализацию хэш-функции для генерации consistent symbolic IDs.
4. Обрезка конфигураций автоподбора
PT2 автоподбор автоматически тестирует множество возможных конфигураций выполнения для каждого ядра, что может быть очень затратно по времени. Был разработан процесс идентификации наиболее затратных ядер и определения оптимальных конфигураций.
5. Оптимизация запуска ядер
Обычные Triton ядра имеют высокую стоимость запуска из-за необходимости генерации C++ во время компиляции. Новый StaticCudaLauncher решает эту проблему.
Проблема времени компиляции в PyTorch 2 — классический пример компромисса между производительностью времени выполнения и накладными расходами на стадии компиляции. Что впечатляет в работе Meta* — это системный подход: они не просто нашли быстрые решения, построили полноценную инфраструктуру анализа и оптимизации. Особое ценное решение с динамической формой маркировки — это тот случай, когда понимание семантики модели позволяет кардинально сократить вычислительные затраты. Интересно, что эти оптимизации универсальны и могут ли они быть применены к другим платформам или войти в стандартную поставку PyTorch.
По материалам PyTorch.
* Meta (признана экстремистской и запрещена в РФ)





Оставить комментарий