
Оглавление
Миграция данных между облачными платформами — одна из самых болезненных задач для инженеров. Различия в диалектах SQL, функциях и типах данных превращают простой, на первый взгляд, процесс переписывания запросов в многомесячный кошмар. Google Cloud предлагает решение с использованием своей языковой модели Gemini для автоматизации перевода SQL из Databricks Spark в BigQuery.
Проблема совместимости SQL-диалектов
Databricks Spark SQL и Google BigQuery, несмотря на общую ANSI SQL основу, имеют фундаментальные различия в реализации. Простой перевод через регулярные выражения невозможен — требуется глубокое понимание семантики обоих диалектов.
Ключевые различия включают:
- Типы данных: TINYINT, SMALLINT в Databricks → INT64 в BigQuery
- Строковые функции: UCase → UPPER
- Временные метки: разная обработка временных зон
- Специализированные функции: особенно в геопространственных вычислениях H3
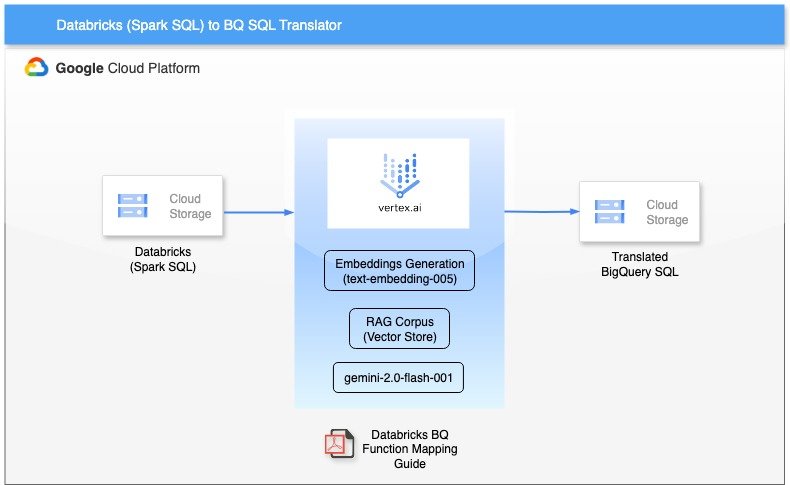
Архитектура решения
Система использует многоуровневый подход для обеспечения точности перевода:
- Исходные SQL-файлы хранятся в Google Cloud Storage
- Создается детальное руководство по сопоставлению функций между платформами
- Подготавливаются примеры качественного ручного перевода для обучения модели
- RAG-слой из Vertex AI обеспечивает контекстуальную информацию для Gemini
- Выполняется проверка через режим прогона в BigQuery
Специфика геопространственных функций
Особую сложность представляют функции работы с H3 — гексагональной иерархической системой геопространственного индексирования. Например:
h3_boundaryasgeojson() в Databricks → ST_ASGEOJSON(jslibs.h3.ST_H3_BOUNDARY()) в BigQueryh3_boundaryaswkb() → ST_ASBINARY(jslibs.h3.ST_H3_BOUNDARY())h3_boundaryaswkt() → ST_ASTEXT(jslibs.h3.ST_H3_BOUNDARY())
Автоматический перевод SQL между платформами — это Святой Грааль инженеров данных. Решение Google выглядит прагматично: вместо попыток создать универсального переводчика они используют комбинацию RAG для контекста и Gemini для генерации. Интересно, насколько этот подход масштабируется на другие пары систем — Snowflake↔Redshift или даже реляционные↔NoSQL БД. Главный вопрос: сколько ручной работы потребуется для подготовки тех самых «качественных примеров перевода» под каждый конкретный кейс.
Практические результаты
По сообщению Google Cloud Blog, комбинация RAG + Gemini значительно повысила точность переводов по сравнению с использованием чистой языковой модели. Ключевые выводы:
- Детальное руководство по сопоставлению функций критически важно
- Проверка через режим прогона предотвращает выполнение некорректных запросов
- Подготовка качественных примеров перевода окупается в долгосрочной перспективе
Решение особенно актуально для компаний, мигрирующих с мультиоблачных архитектур на единую платформу или оптимизирующих затраты через консолидацию стэка данных.





Оставить комментарий