
Оглавление
Компания Databricks анонсировала новую функцию ai_parse_document, которая позволяет преобразовывать PDF-документы в структурированные данные с помощью всего одной SQL-команды. Эта функция стала частью платформы Agent Bricks и находится на стадии публичного предварительного просмотра.
Решение проблемы неструктурированных данных
По оценкам Databricks, около 80% корпоративных данных хранятся в неструктурированном виде — PDF-файлах, отчетах и диаграммах, которые традиционные системы обработки не могут корректно анализировать. Существующие инструменты парсинга ограничиваются извлечением текста, игнорируя таблицы, графики и визуальные элементы, которые несут важную смысловую нагрузку.
Новая функция использует мультимодальные модели для понимания документов целиком:
SELECT
file_name,
ai_parse_document(content) AS parsed_content
FROM READ_FILES('/path/to/documents', format => 'binaryFile');
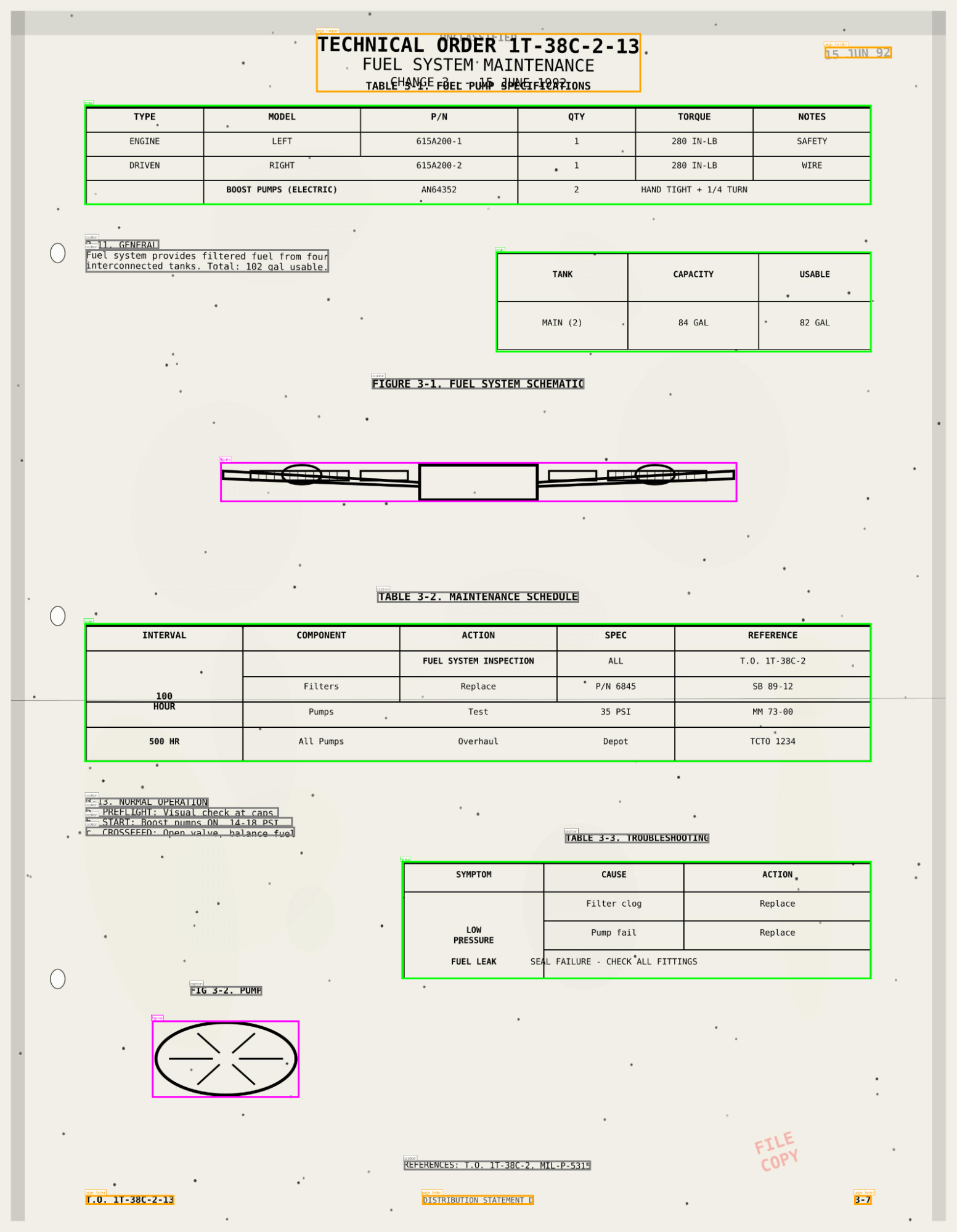
Результат включает не только текст, но и информацию о макете, распознанные таблицы, ограничивающие рамки элементов, изображения с автоматически сгенерированными подписями.
Экономическая эффективность и качество
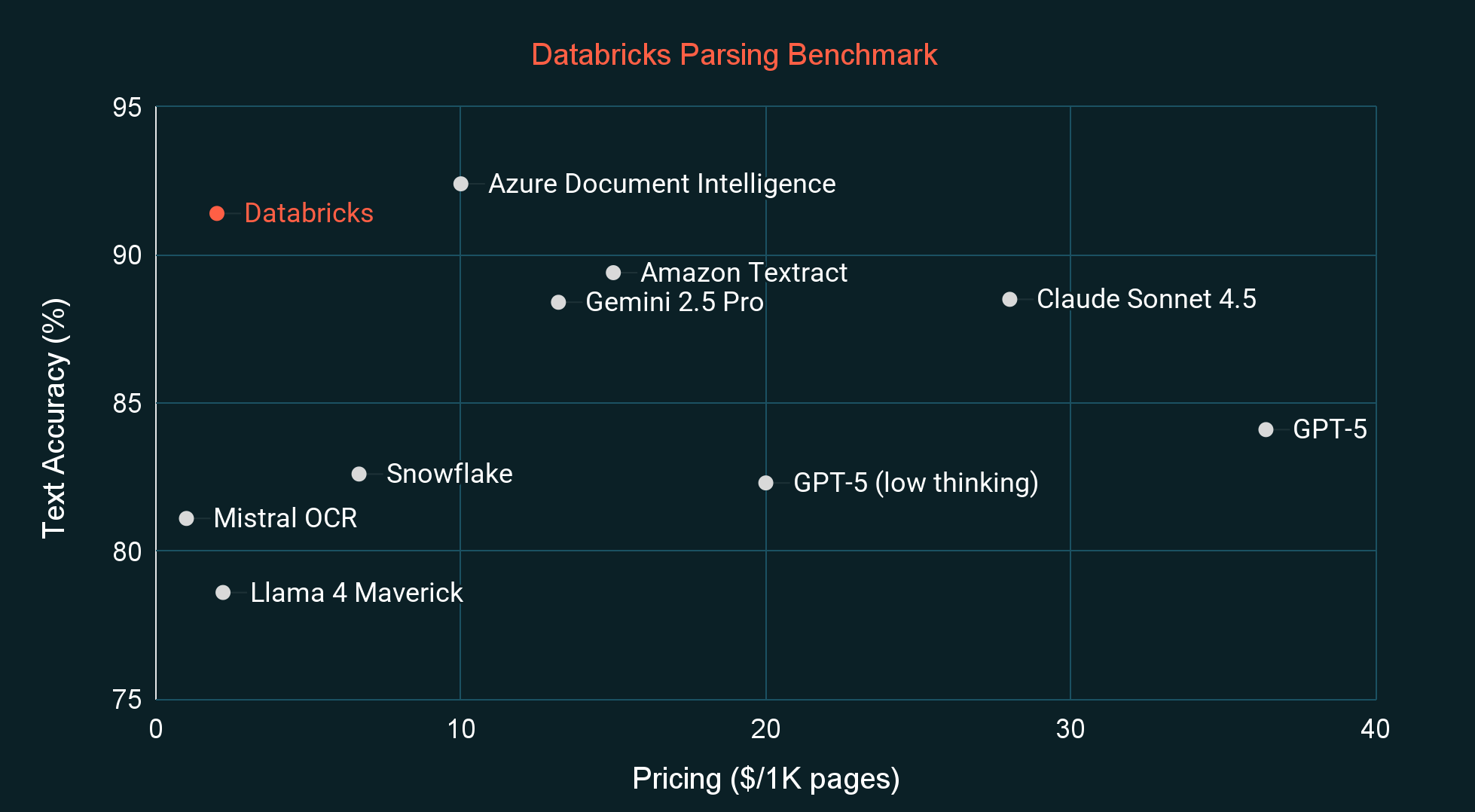
Система демонстрирует конкурентоспособное качество по сравнению с лучшими предложениями на рынке при стоимости обработки в 3-5 раз ниже. Тестирование проводилось как на общедоступном бенчмарке OmniOCR, так и на внутреннем наборе данных Databricks, более точно отражающем реальные корпоративные документы.

Поразительно, как быстро рынок переходит от ручного парсинга документов к полностью автоматизированным решениям. То, что раньше требовало месяцев разработки кастомного кода, теперь умещается в одну SQL-функцию — это серьезный удар по целой индустрии специализированных парсеров.
Интеграция в экосистему Databricks
Функция полностью интегрирована в платформу Databricks:
- Unity Catalog для управления доступом и аудита
- Vector Search для семантического поиска по документам
- Spark Declarative Pipelines для автоматической инкрементальной обработки
- Agent Bricks для построения рабочих процессов с ИИ-агентами
«Извлечение таблиц, текста и метаданных из PDF-файлов или изображений раньше было сложным процессом, требующим большого объема кода. Databricks свела это к одной SQL-функции, радикально упростив обработку неструктурированных данных в масштабе», — отмечает Раджеш Балакришнан, главный специалист по данным в TE Connectivity.
Масштабирование для производственных нужд
Решение предназначено для обработки миллионов документов ежедневно. Интеграция с Spark Declarative Pipelines обеспечивает автоматическую обработку новых документов из SharePoint, S3 или ADLS без необходимости переобработки существующих данных.
«ai_parse_document ускоряет и упрощает RAG на Databricks, позволяя параллельный парсинг документов непосредственно в таблицах Delta, которые вы уже используете», — комментирует Хантер Джонсон, ведущий специалист по данным в Emerson Electric Co.
От парсинга к действию
После обработки данные документов могут использоваться в различных сценариях:
- Vector Search для мультимодальных RAG-приложений
- Declarative Agents для извлечения, классификации и суммаризации
- AI Functions для работы с SQL
- Multi-Agent Supervisor для координации сложных рабочих процессов
Таким образом, неструктурированные данные становятся полноценной частью платформы Agent Bricks.
По материалам Databricks.





Оставить комментарий