
Оглавление
Современные приложения давно перестали быть монолитами — это сложные распределенные системы, где доступность зависит от слаженной работы множества независимых компонентов. Веб-сервер может быть запущен, но если соединение с базой данных прервано или сервис аутентификации не отвечает, все приложение считается неработоспособным. Полагаться на единую проверку здоровья — все равно что доверяться только индикатору «проверьте двигатель», игнорируя проколотое колесо. Да, двигатель работает, но далеко вы не уедете.
Блог Cloudflare сообщает, что компания представляет Monitor Groups для Cloudflare Load Balancing. Эта функция позволяет создавать сложные мультисервисные проверки работоспособности непосредственно на платформе.
Как работают группы мониторинга
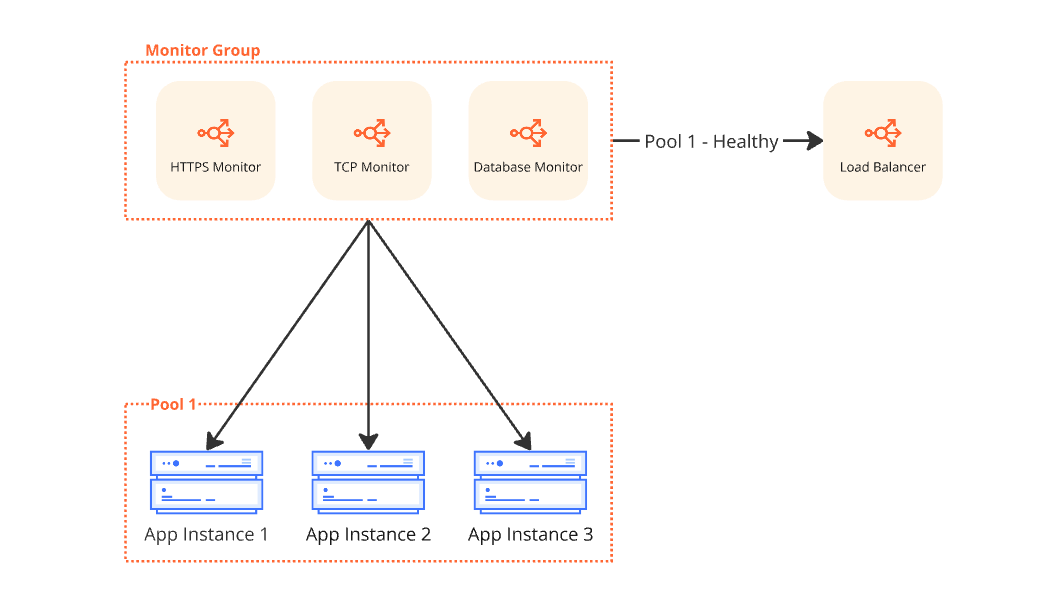
Monitor Groups функционируют как надмножество мониторов. После создания отдельных мониторов их можно объединить в единую логическую группу. При подключении такой группы к пулу эндпоинтов состояние каждого конечного узла определяется агрегированием результатов всех активных мониторов внутри группы.
{
"description": "Test Monitor Group",
"members": [
{
"monitor_id": "string",
"enabled": true,
"monitoring_only": false,
"must_be_healthy": true
},
{
"monitor_id": "string",
"enabled": true,
"monitoring_only": false,
"must_be_healthy": true
}
]
}
Ключевые параметры конфигурации:
- Критические мониторы (must_be_healthy): если монитор с этой настройкой не проходит проверку, эндпоинт немедленно помечается как неработоспособный
- Наблюдательные пробы (monitoring_only): позволяют получать алерты и данные без влияния на маршрутизацию трафика
- Кворумное определение здоровья: в отсутствие критических ошибок статус определяется большинством голосов активных мониторов
В группу можно добавить до пяти мониторов.
Наконец-то облачные провайдеры начинают осознавать, что «работает» и «здорово» — это разные состояния системы. Возможность объединять проверки в логические группы с разными приоритетами — это именно то, что нужно для построения действительно отказоустойчивых архитектур. Особенно ценно, что это избавляет от необходимости строить кастомные агрегаторы проверок, которые сами становятся точками отказа.
Глобально распределенная перспектива
Мощность Monitor Groups усиливается масштабом глобальной сети Cloudflare. Проверки здоровья выполняются не из нескольких статических локаций, а могут быть настроены для запуска из дата-центров в более чем 300 городах по всему миру.
При использовании Dynamic Steering вместе с Monitor Groups задержка рассчитывается как среднее значение Round Trip Time (RTT) всех активных, не-наблюдательных членов группы. Это обеспечивает более стабильную и репрезентативную метрику производительности.
Агрегация здоровья в действии
Рассмотрим пример, демонстрирующий, как Cloudflare агрегирует сигналы здоровья из Monitor Group для определения общего состояния отдельного эндпоинта.
Настройка
- Мониторы в группе:
- HTTP проверка для /health (must_be_healthy: true)
- TCP проверка подключения к порту 3000 (must_be_healthy: false)
- Проверка состояния базы данных (must_be_healthy: false)
- Регионы проверки здоровья:
- Западная Северная Америка (3 дата-центра)
- Восточная Северная Америка (3 дата-центра)
- Порог кворума: Эндпоинт считается здоровым, если более 50% проверяющих дата-центров сообщают о статусе UP.
Сначала Cloudflare определяет состояние здоровья с точки зрения каждого отдельного дата-центра. Если критический монитор не проходит проверку, результат этого дата-центра однозначно определяется как DOWN. В противном случае результат основывается на статусе большинства оставшихся мониторов.
Новая функция доступна через API для корпоративных клиентов и в ближайшем будущем появится в Dashboard для всех пользователей Load Balancing.





Оставить комментарий