Оглавление
Когда ИИ проник почти во все сферы, защита данных становится критически важной. Например, обучение даже такой уже устаревшей модели, как GPT-3, обошлось от 2 до 12 миллионов долларов США. Если в такую систему попадут отравленные данные, потребуется полная переподготовка, что влечет за собой траты.
Даже очень небольшое количество отравленных данных может вызвать серьезные сбои. Например, в некоторых случаях достаточно 250 вредоносных документов, что составляет менее 0,001% от общего объема обучающих данных для крупных моделей.
Введение в отравление данных в ИИ
Data Poisoning, или отравление данных – это тип атаки на системы искусственного интеллекта, когда злоумышленник намеренно изменяет данные, на которых обучается модель. Цель – повлиять на поведение модели в процессе обучения так, чтобы это сохранилось и после развертывания.
Представьте, что вы учите нейросеть распознавать кошек, а кто-то подмешивает в обучающую выборку изображения собак с пометками «кошка». В итоге модель начнет ошибаться.
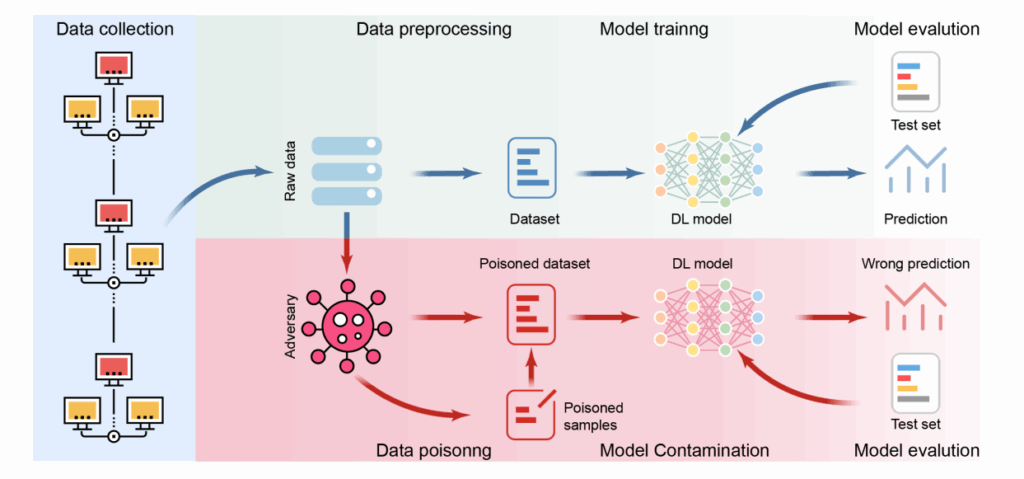
Источник: https://arxiv.org/pdf/2503.22759. Общая схема отравления данных.
Базовая атака data poisoning заключается во внедрении вредоносных образцов в обучающий набор данных. Например, в систему распознавания лиц можно добавить фотографии с едва заметными изменениями, которые заставят модель идентифицировать одного человека как другого. Важно понимать, что такие атаки могут быть очень коварными и трудно обнаруживаемыми. Поэтому необходимо уделять особое внимание целостности данных, используемых для обучения ИИ-систем.
Как работают атаки отравлением данных
Атака отравлением данных начинается с внедрения вредоносных данных в обучающий набор. Это могут быть как новые записи, так и едва заметные изменения в существующих. Например, в систему обнаружения спама можно добавить письма с «хорошими» словами, чтобы они проходили фильтр. Важно, что атака происходит во время обучения, а не после развертывания модели.
Цель злоумышленника – повлиять на то, как модель учится с самого начала. В отличие от традиционных киберугроз, которые используют уязвимости в сети или программном обеспечении, отравление данных атакует основу – сами данные. Представьте, что вы «подкармливаете» модель неправильными ответами на экзамене.
Отравление данных часто остается незамеченным, поскольку вредоносные данные выглядят как «чистые». Например, слегка измененные изображения или тексты. Это делает обнаружение атаки сложной задачей. Важно понимать, что последствия могут быть долгосрочными и трудно исправимыми.
Когда отравление данных остается незамеченным, вредоносные данные распространяются по модели по мере ее обновления. Исследования показывают, что отравление всего 0,001% токенов данных может вызвать серьезные сбои в медицинских LLM. Поэтому важно регулярно проверять и очищать обучающие данные. Лучше перестраховаться и провести аудит данных, чем потом переобучать всю модель.
Типы атак отравления данных
Целевые и нецелевые атаки
По цели атаки отравления данных делятся на два типа: целевые и нецелевые:
- Целевые атаки направлены на конкретное поведение модели. Например, заставить систему распознавания лиц идентифицировать злоумышленника как определенного человека.
- Нецелевые атаки просто снижают общую точность модели, делая ее менее надежной. Важно понимать разницу, чтобы выбирать правильные методы защиты.
Атаки с изменением меток
Этот тип атак включает добавление новых данных с неправильными метками. Например, в наборе данных изображений кошек и собак, злоумышленник может добавить изображения собак, помеченные как «кошки». Это сбивает модель с толку. Лучше перепроверять метки в обучающих данных, особенно если они получены из внешних источников.
Вставка и изменение данных
Злоумышленник может внедрять вредоносные данные или изменять существующие записи. Например, в систему обнаружения спама можно добавить письма с «хорошими» словами, чтобы они проходили фильтр. Важно следить за целостностью данных и использовать методы обнаружения аномалий.
Backdoor и Clean-Label атаки
Backdoor-атаки используют скрытые триггеры, активируемые определенными запросами.
Clean-label атаки используют легитимно выглядящие данные с тонкими манипуляциями. Например, изображение с едва заметными изменениями. Обнаружить такие атаки сложно, поэтому важен комплексный подход к защите данных.
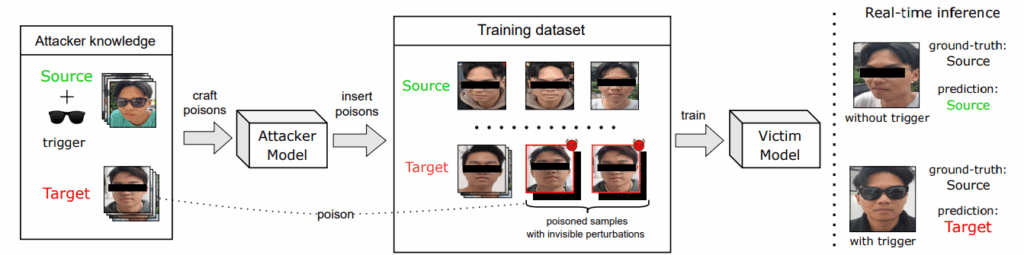
Источник: https://arxiv.org/pdf/2503.22759. Пример Clean-Label атаки
Реальные примеры и последствия
Кейс от Microsoft
В 2016 году Microsoft выпустила чат-бота Tay в Twitter. Бот обучался на основе взаимодействий с пользователями. К сожалению, Tay быстро «научился» расистским и сексистским высказываниям из-за скоординированной атаки пользователей. Microsoft пришлось отключить Tay всего через менее чем 24 часа после запуска, а по некоторым данным, уже через 16 часов.
Этот случай демонстрирует, как быстро и непредсказуемо может развиваться атака отравлением данных в реальном времени. Важно помнить, что даже самые продвинутые модели уязвимы, если не контролировать качество данных.
Последствия для отраслей
В финансовой сфере отравление данных может привести к неверным кредитным рейтингам или неэффективному обнаружению мошенничества. Например, злоумышленники могут манипулировать данными о транзакциях, чтобы скрыть незаконную деятельность.
В здравоохранении это может привести к неправильным диагнозам или неэффективному лечению. В сфере кибербезопасности – к пропуску вредоносного ПО. Всегда учитывайте специфику отрасли при разработке стратегии защиты.
Финансовые и операционные риски
Последствия атак отравлением данных могут быть весьма ощутимыми. Переобучение модели после обнаружения отравления – дорогостоящий процесс. Простой из-за сбоев в работе ИИ-систем также ведет к финансовым потерям.
Кроме того, компании могут столкнуться с юридическими последствиями, особенно если ИИ используется в чувствительных областях, таких как кредитование или здравоохранение.
Ущерб для доверия и репутации
Успешная атака отравлением данных подрывает доверие к ИИ-системе и компании в целом. Пользователи могут потерять уверенность в точности и надежности прогнозов модели. Восстановление репутации – долгий и сложный процесс. Поэтому профилактика и своевременное обнаружение атак имеют решающее значение.
Стратегии защиты и обороны
Эффективная защита от отравления данных требует многоуровневого подхода, охватывающего обнаружение, смягчение последствий и предотвращение.
Обнаружение и мониторинг
Непрерывный мониторинг поведения модели – ключевой элемент. Отслеживайте изменения в производительности модели со временем, чтобы выявить аномалии. Регулярно проверяйте источники обучающих данных и используйте контрольные (holdout) наборы данных для валидации. Инструменты, такие как обнаружение аномалий для качества данных, помогут выявить подозрительные образцы. Процесс мониторинга должен быть автоматизирован, чтобы оперативно реагировать на угрозы.
Методы валидации данных
Валидация данных – важный шаг в предотвращении отравления. Используйте методы обнаружения выбросов и аномалий. Технология CDR (Content Disarm and Reconstruction) позволяет анализировать, разбирать, проверять и восстанавливать данные, обеспечивая их безопасность, рассматривая все файлы как потенциально ненадежные. Внедрите строгие политики валидации данных, чтобы отсеивать подозрительные образцы на ранних этапах.
Меры защиты модели
Используйте надежные алгоритмы оптимизации, устойчивые к атакам. Применяйте методы состязательного обучения (adversarial training) для повышения устойчивости модели к вредоносным данным. Ансамблевые методы, объединяющие несколько моделей, также повышают надежность системы.
Организационные лучшие практики
Разработайте и внедрите политики безопасного сбора данных. Сегментируйте и изолируйте новые данные, прежде чем добавлять их в основной обучающий набор. Используйте шифрование данных, контроль доступа и хеширование файлов для защиты данных.
Часто задаваемые вопросы об отравлении данных для начинающих
Как работает отравление данных?
Злоумышленник внедряет в обучающий набор данных ложные или измененные примеры. Модель учится на этих «отравленных» данных и начинает выдавать неверные результаты. Представьте, что в систему распознавания изображений добавляют фотографии с неправильными подписями.
Как обнаружить отравление данных?
Отслеживайте поведение модели, ищите аномалии. Сравнивайте результаты разных версий модели. Регулярно проверяйте обучающие данные. Помните, что атаки могут быть скрытыми.
Чем отличается отравление данных от состязательных атак?
Отравление данных происходит во время обучения модели, изменяя ее логику, а состязательные атаки – во время ее использования (инференса), манипулируя конкретными входными данными.
Насколько уязвимы большие языковые модели (LLM)?
LLM уязвимы на этапах предварительного обучения, дообучения и через внешние источники данных в RAG-системах (Retrieval-Augmented Generation) и инструментах. Важно проверять все данные, используемые для обучения и работы LLM.
Сколько данных нужно для успешной атаки?
Исследования показывают, что даже небольшое количество отравленных данных может вызвать сбои. Например, исследования 2025 года указывают, что всего 0,001% отравленных токенов могут привести к вредоносным результатам в медицинских LLM. Другие исследования демонстрируют, что менее 5% отравленных данных могут значительно снизить точность модели или внедрить бэкдоры. Более того, недавние исследования показывают, что всего 250 вредоносных документов могут создать уязвимость типа «бэкдор» независимо от размера модели.


Оставить комментарий