
PyTorch сообщает о важном шаге в области оптимизации нейросетей: команды TorchAO, ExecuTorch и Unsloth совместно выпустили предварительно квантованные версии популярных языковых моделей, включая Phi4-mini-instruct, Qwen3, SmolLM3-3B и gemma-3-270m-it. Эти модели используют методы int4 и float8 квантования для эффективного вывода на серверных GPU A100/H100 и мобильных устройствах с минимальной деградацией качества относительно bfloat16-версий.
Технические детали квантования
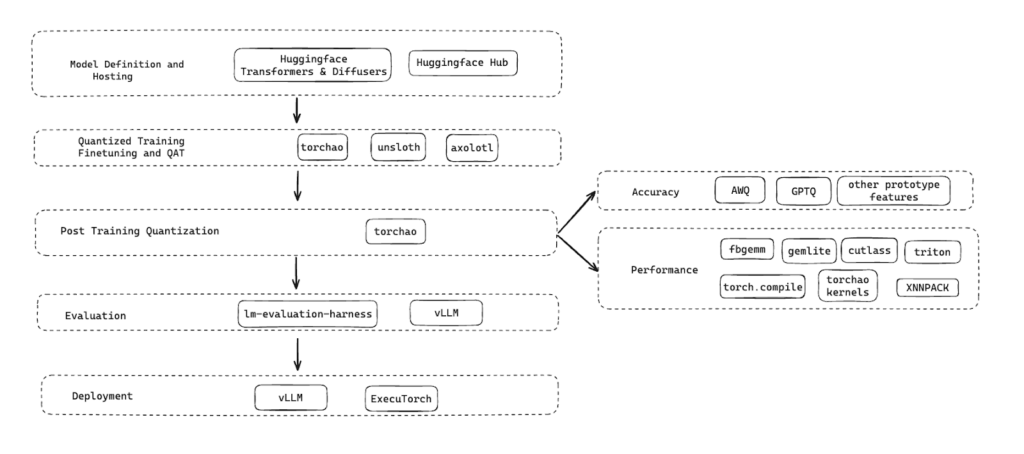
Проект предлагает три основных подхода к квантованию с четким разделением по целевым платформам:
- Int4 weight-only квантование с алгоритмами HQQ и AWQ для серверных GPU H100/A100: ускорение до 1.75x на H100, сокращение памяти на 60%, незначительное снижение точности
- Float8 динамическое квантование активаций и весов для H100: ускорение 1.7-2x, сокращение памяти на 30-40%, практически полное сохранение точности
- Int8/Int4 гибридное квантование для мобильных CPU: возможность запуска на iPhone 15 Pro и Samsung Galaxy S22
Каждая модель сопровождается воспроизводимыми рецептами квантования через библиотеку TorchAO, что позволяет применять те же методы к другим моделям.
Интеграции и экосистема
Квантованные модели интегрированы в экосистему PyTorch с поддержкой всего жизненного цикла: от тонкой настройки через Unsloth до развертывания через FBGEMM и планируемой интеграции с vLLM для серверного вывода.
Квантование из академической темы превращается в инженерную дисциплину с готовыми рецептами. Особенно впечатляет восстановление через AWQ всего с двумя калибровочными образцами — это уровень хирургической точности в оптимизированных моделях. Ждем, когда подобные инструменты станут стандартом для Edge-устройств, где каждый мегабайт памяти на счету.
Дорожная карта и перспективы
В планах команды:
- Квантование MoE-архитектур для инференса и обучения
- Поддержка нового формата NVFP4
- Внедрение дополнительных методов сохранения точности: SmoothQuant, GPTQ, SpinQuant
- Расширение партнерств с Unsloth и vLLM


Оставить комментарий