Оглавление
- Запускаем ИИ на компьютере
- Ollama: Универсальная среда для локальных LLM
- LM Studio: Графический интерфейс для управления моделями
- GPT4All: Простое решение для начинающих
- LocalAI: Локальная замена OpenAI API
- Text Generation Web UI: Расширенный веб-интерфейс
- PrivateGPT: Полностью оффлайн RAG система
- Jan: Элегантный интерфейс для разработчиков
- KoboldAI: Инструмент для творческого письма
- Gaia от AMD: Оптимизированное решение для Windows
- Chatbot UI: Локальный клон ChatGPT
- Сравнительный анализ и рекомендации
Локальные AI-модели открывают принципиально иной подход к работе с языковыми системами — вместо отправки запросов в облако вы запускаете нейросеть непосредственно на своем компьютере.
Запускаем ИИ на компьютере
Ключевое преимущество локального запуска — полный контроль над данными: все ваши диалоги, промпты и конфиденциальная информация остаются на вашем устройстве без передачи третьим сторонам. На практике это ощущается как переход от публичного сервиса к личному инструменту — примерно как разница между использованием онлайн-офиса и установкой полноценного программного пакета.
Технические требования варьируются в зависимости от сложности моделей. Для базовых вариантов вроде Mistral 7B достаточно 8 ГБ оперативной памяти, но для более продвинутых решений типа Llama 3 70B потребуется уже 16 ГБ и более. Поддержка GPU (NVIDIA с CUDA или AMD с ROCm) ускоряет обработку в 3-5 раз — разница особенно заметна при работе с длинными документами. Формат GGUF стал стандартом для эффективной работы на потребительском железе, позволяя загружать только необходимые части модели в память.
Категории локальных инструментов
Можно выделить три основных подхода к локальному запуску. All-in-one решения вроде LM Studio или GPT4All предлагают максимально простой старт — устанавливаете программу, скачиваете модель через встроенный каталог и начинаете работу. Серверные фреймворки типа Ollama или текстовый веб-интерфейс требуют немного технических навыков, но дают больше контроля над параметрами. Низкоуровневые библиотеки вроде llama.cpp или TensorRT-LLM предназначены для разработчиков, желающих интегрировать модели в собственные приложения.
Попробовать базовую установку можно через Ollama — система автоматически подберет оптимальную версию модели для вашего оборудования:
curl -fsSL https://ollama.com/install.sh | sh
ollama pull llama3.1:8b
ollama run llama3.1:8bПосле установки модель доступна через локальный веб-интерфейс или API-эндпоинт. Проверить работоспособность можно запросом к localhost:11434 — сервер должен вернуть статус 200. На старших моделях ответы генерируются со скоростью 10-30 токенов в секунду на среднем CPU, что вполне достаточно для большинства задач.
Кому подходят локальные решения
Локальные модели идеальны для разработчиков, исследователей и компаний с требованиями к конфиденциальности данных. Они незаменимы при работе с коммерческой тайной, персональными данными или чувствительными документами. Экономический расчет простой: единовременные затраты на апгрейд оборудования против ежемесячных подписок на облачные сервисы обычно окупаются за 6-12 месяцев активного использования.
Однако стоит трезво оценивать ограничения: даже мощные локальные модели уступают GPT-5 в сложных задачах на размышление и мультимодальных возможностях.
Требования к дисковому пространству — от 4 ГБ для компактных моделей до 40+ ГБ для продвинутых версий. Если вам нужны максимальная точность в специализированных областях или работа с изображениями — возможно, гибридный подход (локальная модель + избирательное использование облачных API) окажется практичнее.
Ollama: Универсальная среда для локальных LLM
Ollama представляет собой специализированную платформу для развертывания языковых моделей на локальном оборудовании. Подробную информацию можно найти на официальном сайте Ollama. В отличие от графических интерфейсов вроде LM Studio, здесь акцент сделан на работе через командную строку и API — подход, который сначала кажется менее удобным, но на практике дает больше контроля над процессом.
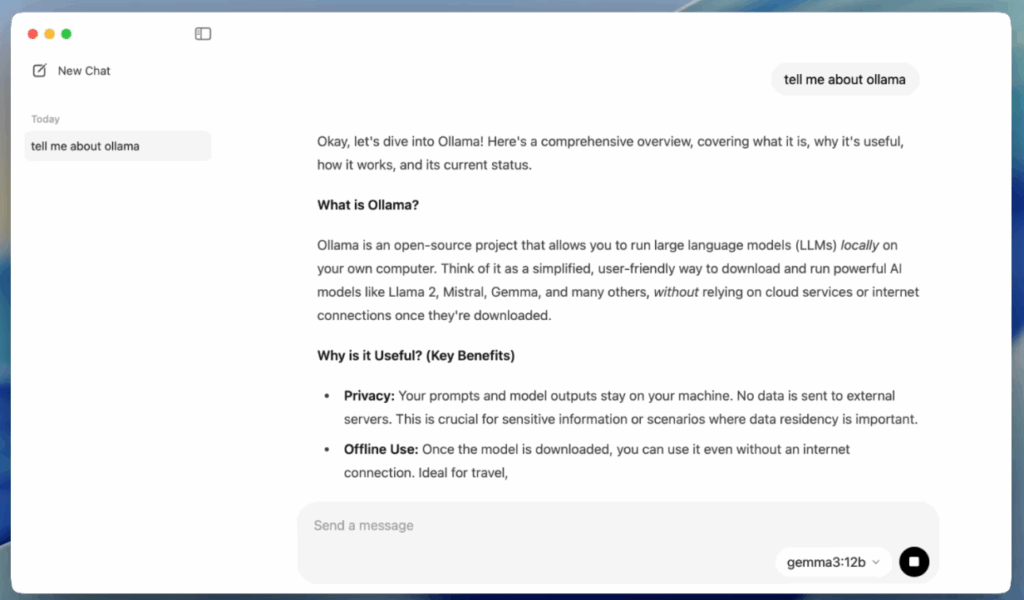
Источник: ollama.com
Установка выполняется единой командой для всех поддерживаемых ОС — Windows, macOS и Linux. Система автоматически определяет архитектуру и подбирает оптимальную версию:
curl -fsSL https://ollama.com/install.sh | shПосле установки сервис запускается автоматически в фоновом режиме. Проверить работоспособность можно запросом к локальному порту 11434 — если сервер отвечает, значит все настроено корректно. На Linux иногда требуется ручной запуск через systemctl, но обычно система справляется самостоятельно.
Загрузка моделей
Базовый набор команд ограничен всего несколькими операциями, но покрывает все основные сценарии работы. Для начала нужно загрузить модель из каталога — система поддерживает десятки вариантов от Llama 3 до специализированных CodeLlama:
ollama pull llama3:8bРазмер скачиваемых файлов варьируется от 4.7 ГБ для компактных моделей до 40+ ГБ для полноразмерных версий. На практике 8-битные варианты демонстрируют разумный баланс между качеством ответов и требованиями к ресурсам. После загрузки модель сразу готова к использованию — дополнительная конфигурация не требуется.
Базовые команды взаимодействия
Основной режим работы — интерактивный чат через командную строку. Запускается одной командой, после чего можно сразу начинать диалог:
ollama run llama3:8bСкорость генерации сильно зависит от оборудования — на современном CPU с 16 ГБ ОЗУ получается около 15-25 токенов в секунду, что ощутимо медленнее облачных решений, но вполне достаточно для большинства задач. Для интеграции в другие приложения доступен REST API по адресу localhost:11434 — эндпоинт /api/generate принимает стандартные промпты и возвращает потоковые ответы.
Важный нюанс: при первом запуске конкретной модели система может занимать несколько минут на дополнительную настройку — это нормально, последующие запуски происходят значительно быстрее. Если планируется частое переключение между разными моделями, лучше держать их все загруженными — они не конфликтуют между собой.
Для разработчиков особенно ценна возможность тонкой настройки параметров генерации — температура, top-p, максимальная длина контекста. Через API это выглядит так:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3:8b",
"prompt": "Объясни теорию относительности",
"stream": false,
"options": {
"temperature": 0.7,
"top_p": 0.9
}
}'Такой подход делает Ollama оптимальным выбором для тех, кому нужен надежный локальный сервер с моделями для интеграции в собственные проекты. Интерфейс минималистичен, но покрывает 95% реальных потребностей.
Инструмент особенно хорошо показывает себя в связке с другими программами через API — например, для автоматизации обработки документов или создания чат-интерфейсов. Для разовых задач удобнее графические решения, но если нужна стабильная работа в фоне с возможностью тонкой настройки — Ollama оказывается практичнее аналогов.
LM Studio: Графический интерфейс для управления моделями
LM Studio предлагает принципиально иной подход к работе с локальными языковыми моделями — вместо командной строки вы получаете полноценное десктопное приложение с визуальным интерфейсом. Установка занимает минуты: скачиваете исполняемый файл с официального сайта LM Studio, запускаете установщик — система автоматически определяет платформу и настраивает окружение. Проверить успешность установки можно по наличию иконки в системном трее — приложение работает в фоне, готовое к работе.
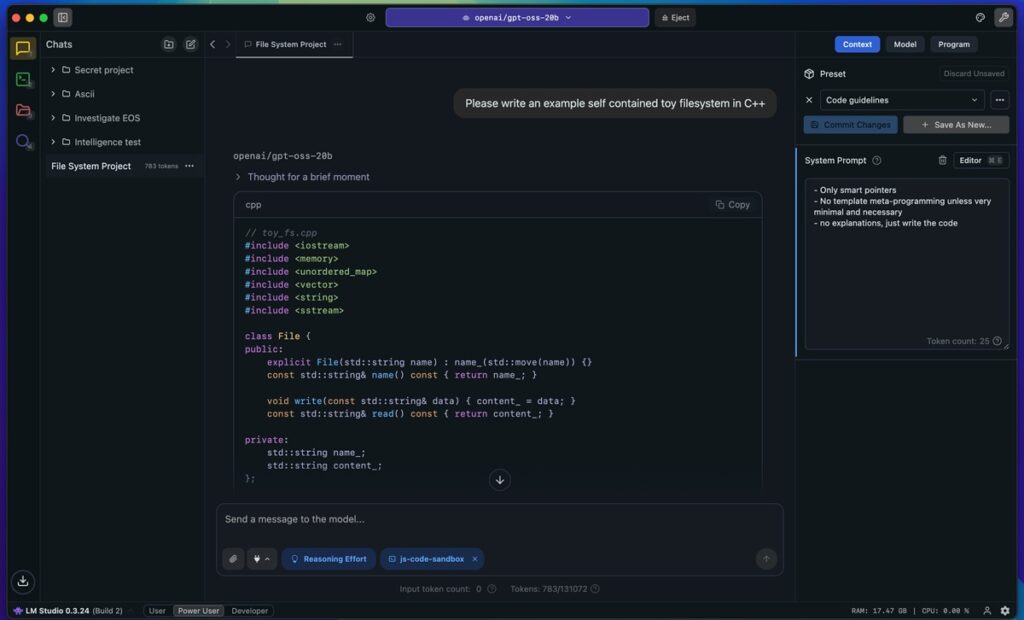
Источник: lmstudio.ai
Первое впечатление: интерфейс кажется перегруженным, но через 10-15 минут понимаешь логику расположения элементов. В левой панели — меню моделей, центральная часть отведена под чат, справа — настройки параметров генерации. По сравнению с текстовыми интерфейсами ощущается как переход от терминала к полноценной IDE — все инструменты под рукой, но нужно время на освоение.
Импорт моделей
Ключевое преимущество LM Studio — встроенный каталог моделей с фильтрацией по типу, размеру и рейтингу. Открываете вкладку «Discover», выбираете нужную модель из списка (поддерживаются репозитории Hugging Face и TheBloke), нажимаете Download — система самостоятельно загружает GGUF-файл и добавляет его в локальную библиотеку. Формат GGUF оптимален для потребительского оборудования — модели занимают меньше места и эффективнее используют оперативную память.
На практике загрузка 7-миллиардной модели занимает 5-10 минут при быстром интернете. После завершения загрузки модель появляется в списке доступных — достаточно кликнуть на нее, чтобы активировать. Проверить корректность загрузки можно через вкладку «Model» — там отображается точное название, размер контекста и версия квантизации. Если модель не загружается, проверьте свободное место на диске — некоторые варианты занимают 8-10 ГБ.
Настройка API сервера
Скрытая особенность LM Studio — встроенный REST API сервер, совместимый с OpenAI-клиентами. Активируется через меню «Local Server» — включаете переключатель, система автоматически запускает сервер на localhost:1234(обратите внимание: с /v1 в URL могут быть проблемы). Проверить работоспособность можно стандартным curl-запросом:
curl http://localhost:1234/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "current",
"messages": [{"role": "user", "content": "Привет, как дела?"}],
"temperature": 0.7
}'Сервер должен вернуть JSON-ответ сгенерированным текстом. Это открывает возможности интеграции с существующими приложениями — от чат-ботов до систем автоматизации документации. На практике API работает стабильно, выдерживает несколько одновременных подключений без заметного падения производительности.
Важный нюанс: при переключении моделей через интерфейс сервер автоматически обновляет активную модель — не нужно перезапускать службу. Однако если планируется интенсивное использование API, лучше отключить автоматическую загрузку моделей при старте — иначе приложение будет занимать лишнюю оперативную память.
LM Studio оптимально подходит для исследователей и разработчиков, которым нужен быстрый старт без погружения в технические детали. Интерфейс интуитивен, каталог моделей избавляет от ручного поиска GGUF-файлов, а совместимость с OpenAI API позволяет интегрировать локальные модели в существующие проекты. Для продакшен-сред с высокими нагрузками лучше рассмотреть серверные решения, но для персонального использования и прототипирования LM Studio оказывается удобнее аналогов.
GPT4All: Простое решение для начинающих
GPT4All позиционируется как максимально доступный входной порог в мир локальных языковых моделей. После установки приложения размером около 200 МБ вы получаете готовую среду с предварительно настроенными моделями — никаких консольных команд или ручной настройки параметров. Интерфейс напоминает упрощенную версию ChatGPT: слева список диалогов, центральная область для общения, в правой панели — базовые настройки температуры и длины ответа.
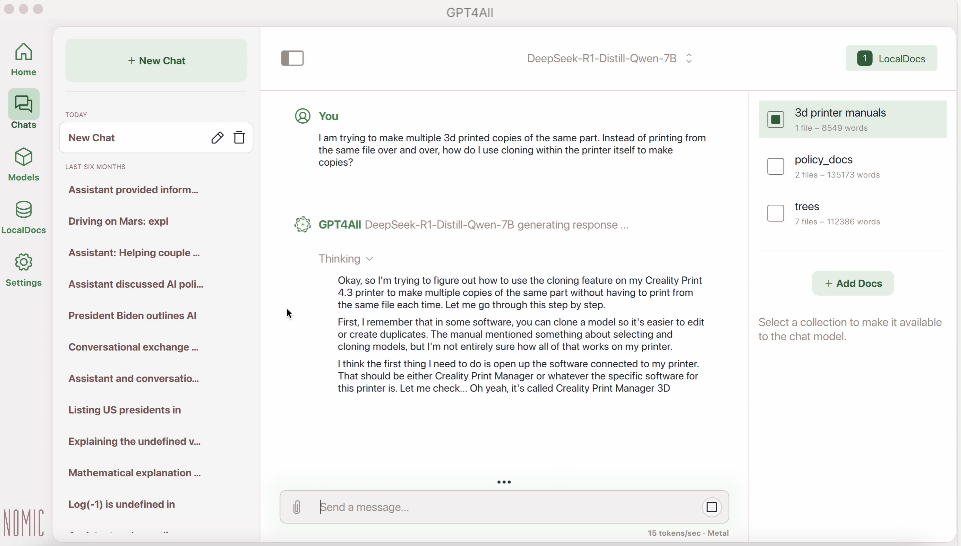
Источник: nomic.ai/gpt4all
Первое впечатление: установка действительно занимает минуты, но стартовые модели оказываются слишком ограниченными. Система предлагает загрузить варианты на 3-7 ГБ, которые быстро справляются с простыми запросами, но спотыкаются на сложных рассуждениях. Интерфейс сначала кажется излишне минималистичным — нет тонкой настройки генерации или продвинутых параметров, но для базовых задач этого хватает.
Работа с моделями
Встроенный магазин моделей содержит десятки вариантов от Mistral до специализированных CodeLlama, но автоматически рекомендует только проверенные стабильные версии. Загрузка начинается сразу после клика — прогресс отображается в нижней панели. На практике 7-миллиардные модели показывают лучший баланс скорости и качества на оборудовании с 8 ГБ ОЗУ, но для сложных задач лучше сразу искать 13-миллиардные версии.
После загрузки модель автоматически становится активной — переключение между разными вариантами занимает секунды. Проверить корректность работы можно простым тестовым запросом:
# Модель должна давать связный ответ на русском языке
# без технических ошибок и обрыва генерацииЕсли ответы обрываются на полуслове или содержат бессмысленные повторения — вероятно, не хватает оперативной памяти. В таких случаях помогает перезагрузка приложения или выбор менее требовательной модели.
Сильные и слабые стороны
Главное преимущество — кроссплатформенность и стабильность. Приложение одинаково работает на Windows, macOS и Linux без дополнительной настройки. Интерфейс не перегружен лишними элементами, что идеально для новичков. Поддержка темной темы и локального хранения всей истории диалогов добавляет комфорта при ежедневном использовании.
Однако простота оборачивается ограничениями: нет доступа к низкоуровневым параметрам вроде top-p или penalty настроек, отсутствует API для интеграции с другими приложениями. Модели загружаются только через встроенный каталог — ручная установка GGUF-файлов не поддерживается. На устройствах с ровно 8 ГБ ОЗУ могут возникать подтормаживания при одновременной работе с другими программами.
Практический вывод: GPT4All оптимален для пользователей, которым нужен быстрый старт без технических сложностей. Подходит для простых консультаций, базовой помощи в написании текстов и образовательных целей. Не стоит выбирать это решение для коммерческих проектов, работы с конфиденциальными документами или задач, требующих стабильного API — здесь лучше подойдут Ollama или LM Studio. Для знакомства с локальными LLM — один из лучших вариантов на рынке.
LocalAI: Локальная замена OpenAI API
LocalAI — это контейнеризированное решение для развертывания локальных языковых моделей с полной совместимостью с OpenAI API. В отличие от ранее рассмотренных инструментов, фокус здесь сделан на эмуляции облачной инфраструктуры — вы получаете идентичные эндпоинты, но все данные обрабатываются локально. Такой подход особенно ценен для разработчиков, мигрирующих с облачных API на собственные серверы.
Источник: github.com/mudler/LocalAI
Начало работы требует предварительной установки Docker — системы контейнеризации, обеспечивающей изоляцию окружения и воспроизводимость. Проверить наличие Docker можно командой:
docker --versionЕсли команда возвращает ошибку, потребуется установить его с помощью официального установщика для вашей ОС. На Linux процесс обычно выглядит так:
curl -fsSL https://get.docker.sh -o get-docker.sh
sudo sh get-docker.shПосле установки обязательно добавьте текущего пользователя в группу docker для работы без sudo — иначе столкнетесь с постоянными запросами прав администратора.
Запуск контейнера LocalAI
Базовый запуск выполняется одной командой — система автоматически загрузит образ из Docker Hub и развернет контейнер на порту 8080:
docker run -p 8080:8080 localai/localai:latest-cpuПервоначальная загрузка занимает 2-5 минут в зависимости от скорости интернета. Критерий успешного запуска — появление в логах сообщения о готовности сервера и отсутствие ошибок инициализации. Если порт 8080 занят другим приложением, можно изменить маппинг на любой свободный порт:
docker run -p 9090:8080 localai/localai:latest-cpuНа практике контейнеризированная реализация обеспечивает лучшую стабильность по сравнению с нативными установками — зависимости изолированы, а конфликты версий устранены. Однако размер образа превышает 4 ГБ, что требует значительного дискового пространства.
Конфигурация моделей и API
После запуска сервера необходимо настроить модели — по умолчанию контейнер пуст. Модели загружаются через REST API или размещаются в подключенном томе. Базовый тест функциональности с помощью стандартного запроса, совместимого с OpenAI:
curl http://localhost:8080/v1/modelsСервер должен вернуть JSON со списком доступных моделей. Чтобы добавить конкретную модель, нужно использовать эндпоинт /models/apply, указав имя и источник загрузки. LocalAI поддерживает форматы GGUF и ONNX — первый оптимален для CPU, второй эффективнее на GPU.
Ключевое преимущество — полная совместимость с существующими клиентами OpenAI. Например, работа через библиотеку Python openai требует почти никаких изменений кода:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="none"
)
response = client.chat.completions.create(
model="local-model",
messages=[{"role": "user", "content": "Объясни квантовые вычисления"}]
)На практике миграция с облачного OpenAI на LocalAI занимает минуты — достаточно изменить base_url и отключить проверку SSL. Эндпоинты /v1/chat/completions, /v1/embeddings и /v1/models работают идентично оригиналам.
Особенности эксплуатации
Для продакшен-использования рекомендуется монтировать внешние директории для моделей и конфигураций — иначе все данные будут потеряны при пересоздании контейнера:
docker run -p 8080:8080 -v ./models:/models localai/localai:latest-cpuПроизводительность сильно зависит от выбранной модели и оборудования. На CPU с 16 ГБ ОЗУ модели с 7 миллиардами параметров выдают 8-12 токенов в секунду — достаточно для фоновых задач, но интерактивное использование кажется медленным. Поддержка GPU через CUDA ускоряет обработку в 3-5 раз, но требует специальных образов с поддержкой NVIDIA.
LocalAI оптимален для разработчиков, создающих приложения, требующие конфиденциальности данных или работающие в изолированных сетях. Полная совместимость с OpenAI API позволяет использовать существующие инструменты и библиотеки без модификаций. Для простого чата лучше подойдут Ollama или LM Studio, но если нужна промышленная замена облачной инфраструктуре, LocalAI оказывается единственным полноценным решением. Репозиторий LocalAI есть на GitHub
Text Generation Web UI: Расширенный веб-интерфейс
Text Generation Web UI представляет собой многофункциональную веб-платформу для работы с локальными языковыми моделями, отличающуюся от рассмотренных ранее решений расширенной кастомизацией и поддержкой плагинов. В отличие от готовых приложений вроде LM Studio, здесь требуется ручная установка через GitHub-репозиторий, что обеспечивает большую гибкость, но требует технической подготовки. После настройки система поддерживает десятки моделей включая Vicuna, Mistral и Falcon с различными режимами работы — от классического чата до сложных ролевых сценариев.
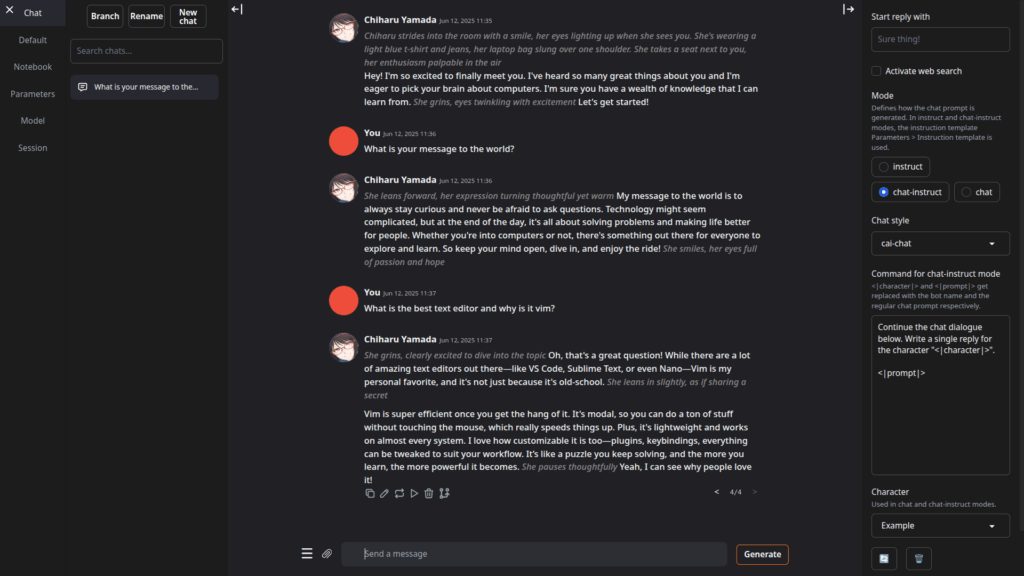
Первое впечатление: интерфейс кажется перегруженным — десятки вкладок и настроек могут отпугнуть новичков. Однако через 30-40 минут использования понимаешь логику организации: базовые функции вынесены на главный экран, специализированные настройки скрыты в расширенных меню. По сравнению с минималистичным GPT4All разница ощутима как между блокнотом и полноценным текстовым редактором.
Установка зависимостей
Начинается процесс с клонирования репозитория и настройки окружения. Рекомендуется использовать Conda для изоляции зависимостей — это предотвращает конфликты версий Python-библиотек:
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
conda create -n textgen python=3.11
conda activate textgenПосле активации окружения устанавливаются основные зависимости через pip. На этом этапе часто возникают ошибки совместимости — лучше использовать точные версии из requirements.txt:
pip install -r requirements.txtПроверить корректность установки можно попыткой запуска сервера — если не появляется ошибок импорта модулей, значит окружение настроено правильно. На системах с NVIDIA GPU дополнительно потребуется установка CUDA-совместимых версий torch — без этого ускорение на видеокарте работать не будет.
Запуск интерфейса
Базовый запуск выполняется через Python-скрипт, который инициализирует веб-сервер на стандартном порту 7860:
python server.pyПосле успешного запуска в консоли появится сообщение с URL для доступа к интерфейсу — обычно http://localhost:7860. Критерий правильной работы — веб-страница загружается без ошибок в браузере, а в терминале отсутствуют сообщения об исключениях. Первая загрузка может занимать 1-2 минуты — система инициализирует компоненты и проверяет доступность моделей.
На практике сервер стабильно работает неделями без перезапуска, но при частом переключении между тяжелыми моделями может потребоваться очистка памяти. Если интерфейс не открывается, проверьте что порт 7860 не занят другим приложением — в таких случаях помогает изменение порта через аргумент —listen-port.
Настройка плагинов
Ключевое преимущество платформы — модульная архитектура с поддержкой плагинов. Базовый набор включает voice-to-text для голосового ввода, memory для сохранения контекста между сессиями и расширения для работы с эмбеддингами. Активация плагинов происходит через файл конфигурации или веб-интерфейс:
python server.py --extensions voice_input, memoryПосле перезапуска сервера новые функции появляются в соответствующих разделах интерфейса. Голосовой ввод требует дополнительной настройки аудиодрайверов — на Linux могут понадобиться пакеты alsa-utils, на Windows система обычно справляется автоматически. Плагин memory оказался наиболее полезным на практике — он сохраняет историю диалогов в структурированном виде и позволяет возобновлять обсуждение сложных тем через дни или недели.
Важный нюанс: некоторые плагины конфликтуют между собой — особенно при одновременной работе с embeddings и голосовым управлением. Лучше активировать только необходимые расширения, а не все доступные. Проверить работоспособность каждого плагина можно через тестовые сценарии — например, для voice_input достаточно произнести короткую фразу и убедиться что она корректно преобразуется в текст.
Text Generation Web UI оптимален для продвинутых пользователей, которым недостаточно возможностей Ollama или LM Studio. Поддерживаемые режимы чата, инструкций и ролевых игр покрывают большинство сценариев работы с языковыми моделями. Не стоит выбирать это решение для разового использования или на слабом оборудовании — требования к памяти и вычислительным ресурсам здесь значительно выше. Однако для исследователей и разработчиков, нуждающихся в максимальном контроле над процессом генерации, альтернатив практически нет. Репозитоой тоже есть на GitHub.
PrivateGPT: Полностью оффлайн RAG система
PrivateGPT предлагает принципиально иной подход к работе с документами — вместо отправки файлов в облачные сервисы вы создаете локальную систему вопрос-ответ на основе собственных материалов. Архитектура построена вокруг RAG (Retrieval-Augmented Generation) — технологии, которая сначала находит релевантные фрагменты в документах, а затем генерирует ответ на их основе. На практике это ощущается как создание персонального эксперта по вашим данным, доступного даже без интернет-соединения.
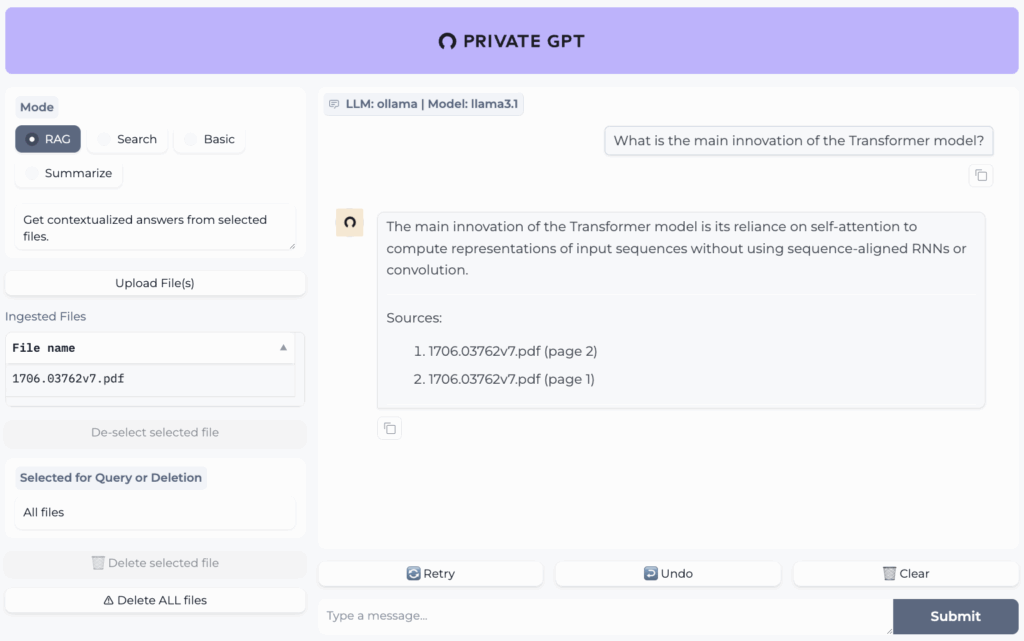
Источник: github.com/zylon-ai/private-gpt
Первое впечатление: установка требует больше шагов по сравнению с готовыми приложениями, но результат того стоит. Система не просто отвечает на вопросы, а точно цитирует источники из ваших документов с указанием страниц и файлов. Интерфейс сначала кажется спартанским — только командная строка, но через 10-15 минут понимаешь, что это компенсируется точностью ответов.
Подготовка документов
Начинается процесс с помещения файлов в специальную папку ingest — система поддерживает PDF, DOCX, TXT и другие распространенные форматы. Критически важно проверять кодировку текстовых файлов — UTF-8 работает стабильно, а вот Windows-1251 может вызвать проблемы с распознаванием кириллицы:
mkdir -p privateGPT/ingest
cp документы/*.pdf privateGPT/ingest/После размещения файлов запускается процесс индексации — система преобразует текст в векторные представления и сохраняет их в локальную базу данных Chroma. На этом этапе часто возникают ошибки с поврежденными PDF — лучше предварительно проверять файлы на возможность выделения текста. Для документов со сканированным текстом потребуется предварительное распознавание через OCR-инструменты.
Настройка RAG
Основная конфигурация происходит через environment-файл, где задаются параметры embedding-модели и языковой модели. По умолчанию используется sentence-transformers для векторных представлений и GGUF-модели для генерации ответов. Проверить корректность настройки можно запуском тестового сценария:
python ingest.py
python privateGPT.pyПосле успешной индексации система переходит в интерактивный режим — задаете вопрос на естественном языке, PrivateGPT находит релевантные фрагменты в документах и формирует развернутый ответ. Критерий правильной работы — ответы содержат точные цитаты из исходных материалов с указанием источников.
Важный нюанс: качество ответов напрямую зависит от объема и структуры исходных документов. На 10-20 страницах текста система работает идеально, но при обработке тысяч страниц может потребоваться тонкая настройка параметров chunk_size и chunk_overlap для оптимального разделения текста. Если ответы кажутся поверхностными — вероятно, нужно увеличить количество возвращаемых контекстных фрагментов.
На практике PrivateGPT демонстрирует лучшие результаты с технической и юридической документацией, где важна точность цитирования. Скорость генерации зависит от выбранной языковой модели — 7-миллиардные варианты работают достаточно быстро даже на CPU, но для сложных запросов лучше использовать 13-миллиардные модели. Потребление оперативной памяти варьируется от 8 ГБ для базовых сценариев до 16+ ГБ при работе с большими коллекциями документов.
Система идеально подходит для исследователей, юристов и аналитиков, работающих с конфиденциальными документами. Полная оффлайн-работа гарантирует защиту данных, а точное цитирование источников делает ответы достоверными. Не стоит выбирать PrivateGPT для разовых задач или на слабом оборудовании — требования к ресурсам здесь выше, чем у простых чат-интерфейсов. Однако для создания корпоративных экспертных систем или работы с коммерческой тайной это одно из немногих полнофункциональных решений.
Jan: Элегантный интерфейс для разработчиков
Jan представляет собой десктопное приложение с интерфейсом в стиле современных macOS-приложений, ориентированное на разработчиков, работающих с локальными языковыми моделями. В отличие от веб-интерфейсов вроде Text Generation Web UI, здесь акцент сделан на минимализме и интеграции с существующими бэкендами — система работает как универсальный клиент для Ollama, Hugging Face и других сервисов.
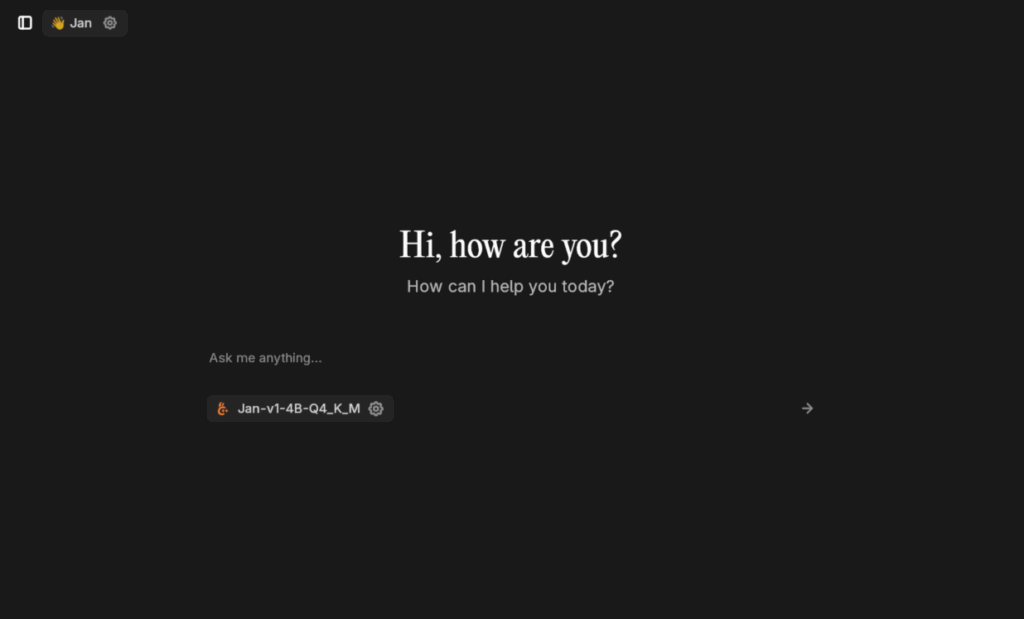
Источник: jan.ai
Первое впечатление: интерфейс сначала кажется слишком пустым — нет перегруженных панелей настроек или десятков вкладок. Однако через 15-20 минут использования понимаешь преимущество такого подхода — все необходимое для работы с кодом и текстом под рукой, но ничего лишнего. По сравнению с LM Studio ощущается как переход от тяжелой IDE к минималистичному редактору вроде Sublime Text.
Установка зависимостей
Начинается процесс с клонирования репозитория и установки npm-пакетов. Система требует Node.js версии 18 или выше — проверьте соответствие перед началом установки:
git clone https://github.com/janhq/jan
cd jan
npm installПроцесс установки занимает 3-7 минут в зависимости от скорости интернета и производительности системы. На этом этапе часто возникают ошибки совместимости версий Node.js — если npm выдает предупреждения, лучше обновить Node.js до LTS-версии. Проверить корректность установки можно попыткой запуска dev-режима:
npm run devПри успешном запуске в терминале появится сообщение с портом для доступа к интерфейсу — обычно это localhost:3000. Критерий правильной работы — веб-интерфейс загружается без ошибок в браузере, а в консоли отсутствуют сообщения об исключениях.
Настройка бэкендов
Ключевое преимущество Jan — универсальность подключения к различным бэкендам. Система не содержит встроенных моделей, а выступает клиентом для уже настроенных сервисов. Настройка подключения к Ollama занимает секунды — достаточно указать адрес сервера в настройках:
# Предварительно должен быть запущен Ollama
ollama serveВ интерфейсе Jan переходите в раздел Settings > Backends, добавляете новый эндпоинт с типом Ollama и адресом http://localhost:11434. Система автоматически определит доступные модели и загрузит их список. Проверить корректность подключения можно созданием нового чата — в селекторе моделей должны появиться варианты из Ollama.
Важный нюанс: при работе с Hugging Face потребуется указать API-ключ в настройках — без него система сможет показывать доступные модели, но не сможет их загружать. Если планируется интенсивная работа с разными бэкендами, лучше создавать отдельные пространства для каждого типа задач — это предотвратит конфликты конфигураций.
На практике Jan особенно хорошо показывает себя на Mac с чипами M1/M2/M3 — интерфейс работает плавно, потребление памяти минимальное. Поддержка NVIDIA GPU через CUDA доступна при использовании соответствующих бэкендов, но требует дополнительной настройки на уровне серверной части. Для разработчиков, уже использующих Ollama или аналогичные решения, Jan становится идеальной прослойкой — сохраняется вся функциональность бэкендов, но добавляется удобный интерфейс с поддержкой тем, истории чатов и экспорта диалогов.
Система оптимальна для программистов и технических писателей, которым нужен чистый интерфейс для работы с кодом без отвлекающих элементов. Поддержка синтаксиса различных языков программирования и форматирования Markdown делает ее удобной для обсуждения технических вопросов. Не стоит выбирать Jan как самостоятельное решение — без предварительно настроенных бэкендов это просто пустая оболочка. Однако в сочетании с Ollama или Hugging Face он оказывается практичнее большинства аналогов для повседневной работы с локальными моделями.
KoboldAI: Инструмент для творческого письма
KoboldAI представляет собой специализированный клиент для генерации текстов с акцентом на творческие задачи — создание диалогов, разработка сюжетных линий и написание художественных произведений. В отличие от универсальных решений вроде Ollama, здесь интерфейс изначально заточен под нужды писателей и сценаристов, с поддержкой управления персонажами, ведением сюжетных веток и тонкой настройкой стиля генерации. После установки система работает как локальный веб-сервер, предоставляя доступ через браузер с любого устройства в сети.
Первое впечатление: интерфейс кажется архаичным по сравнению с современными аналогами, но через 20-30 минут работы понимаешь его логику — все элементы организованы вокруг рабочего процесса писателя. Центральная область для текста, справа — панель управления генерацией, снизу — история действий. По сравнению с минималистичными интерфейсами ощущается как переход от блокнота к специализированному редактору сценариев.
Установка и настройка клиента
Начинается процесс с клонирования репозитория и установки Python-зависимостей. Система требует Python 3.8+ и совместима с большинством дистрибутивов Linux, Windows и macOS:
git clone https://github.com/KoboldAI/KoboldAI-Client
cd KoboldAI-Client
pip install -r requirements.txtПосле установки зависимостей запускается веб-сервер командой `play.sh` для Linux/macOS или `play.bat` для Windows. Система автоматически определяет доступное оборудование и настраивает параметры для оптимальной производительности. Критерий успешного запуска — появление в консоли сообщения с адресом для доступа к интерфейсу, обычно http://localhost:5000.
Важный нюанс: при первом запуске система может занимать 5-10 минут на инициализацию компонентов — это нормально, последующие запуски происходят значительно быстрее. Если порт 5000 занят другим приложением, можно изменить его через аргументы командной строки или редактирование конфигурационного файла.
Выбор и загрузка моделей
KoboldAI поддерживает широкий спектр языковых моделей в форматах GGUF и GPT-J, с автоматической оптимизацией для творческих задач. Модели загружаются через встроенный менеджер — открываете вкладку «Model», выбираете подходящий вариант из каталога или указываете путь к локальному файлу. Для диалоговых сценариев лучше подходят модели, обученные на художественных текстах и диалогах, тогда как для повествования эффективнее варианты с акцентом на описательные способности.
После выбора модели система автоматически применяет предустановленные параметры для творческого письма. Проверить корректность загрузки можно через тестовую генерацию — если текст получается связным и соответствует заданному стилю, значит модель работает правильно. На слабом оборудовании с 8 ГБ ОЗУ лучше начинать с 7-миллиардных моделей — они демонстрируют разумный баланс между качеством и производительностью.
Настройка параметров генерации
Ключевое преимущество KoboldAI — детальный контроль над процессом генерации через параметры temperature, top_p и repetition penalty. Temperature регулирует случайность выводов: значения 0.7-0.9 дают креативные, но иногда непредсказуемые результаты, тогда как 0.3-0.5 обеспечивают более стабильное и предсказуемое повествование. Top_p (nucleus sampling) контролирует разнообразие словарного запаса — значения 0.8-0.95 оптимальны для художественных текстов.
Repetition penalty особенно важен для длинных произведений — параметр предотвращает зацикливание на одних и тех же фразах и конструкциях. На практике значение 1.1-1.2 эффективно борется с повторами, не делая текст неестественным. Все параметры можно настраивать в реальном времени durante генерации, наблюдая как изменения влияют на стиль output.
Практический пример: при работе над диалогом между персонажами помогает комбинация temperature=0.8, top_p=0.9 и repetition penalty=1.15 — персонажи сохраняют индивидуальность речи, но не скатываются в бессвязные монологи. Для описательных passages лучше подходит temperature=0.6 с более консервативным top_p=0.85 — это обеспечивает последовательность изложения без потери художественности.
Сетевые возможности и коллаборация
Интересная особенность — поддержка сети Horde, позволяющей объединять вычислительные ресурсы нескольких пользователей для ускорения генерации. В режиме Horde ваши запросы могут обрабатываться на мощностях других участников сети, а вы в свою очередь делитесь своими ресурсами в периоды простоя. На практике это дает ускорение в 2-3 раза на слабом оборудовании, но требует стабильного интернет-соединения.
Для локальной работы в группе доступен режим многопользовательского редактирования — несколько писателей могут одновременно работать над одним произведением, видя изменения друг друга в реальном времени. Функция оказалась полезной при создании сценариев и коллективных романов, где важно сохранять единый стиль повествования.
KoboldAI оптимален для писателей, сценаристов и создателей игрового контента, которым нужен специализированный инструмент для генерации художественных текстов. Система демонстрирует лучшие результаты в задачах создания диалогов, разработки сюжетных поворотов и описания персонажей. Не стоит выбирать это решение для технических документов или аналитических задач — здесь специализированные модели показывают себя слабее универсальных аналогов. Однако для творческих проектов, где важны стилистическое единство и управление повествовательной структурой, KoboldAI оказывается практичнее большинства рассмотренных альтернатив.
Gaia от AMD: Оптимизированное решение для Windows
Gaia представляет собой специализированный фреймворк для развертывания локальных языковых моделей с акцентом на интеграцию с оборудованием AMD. В отличие от универсальных решений вроде Ollama, здесь архитектура изначально оптимизирована под процессоры Ryzen с AI-ускорителями, что обеспечивает заметный прирост производительности при работе с моделями среднего размера. После установки система работает как локальный сервер с веб-интерфейсом, предлагая готовых агентов для различных сценариев — от простого чата до анализа документов через RAG.
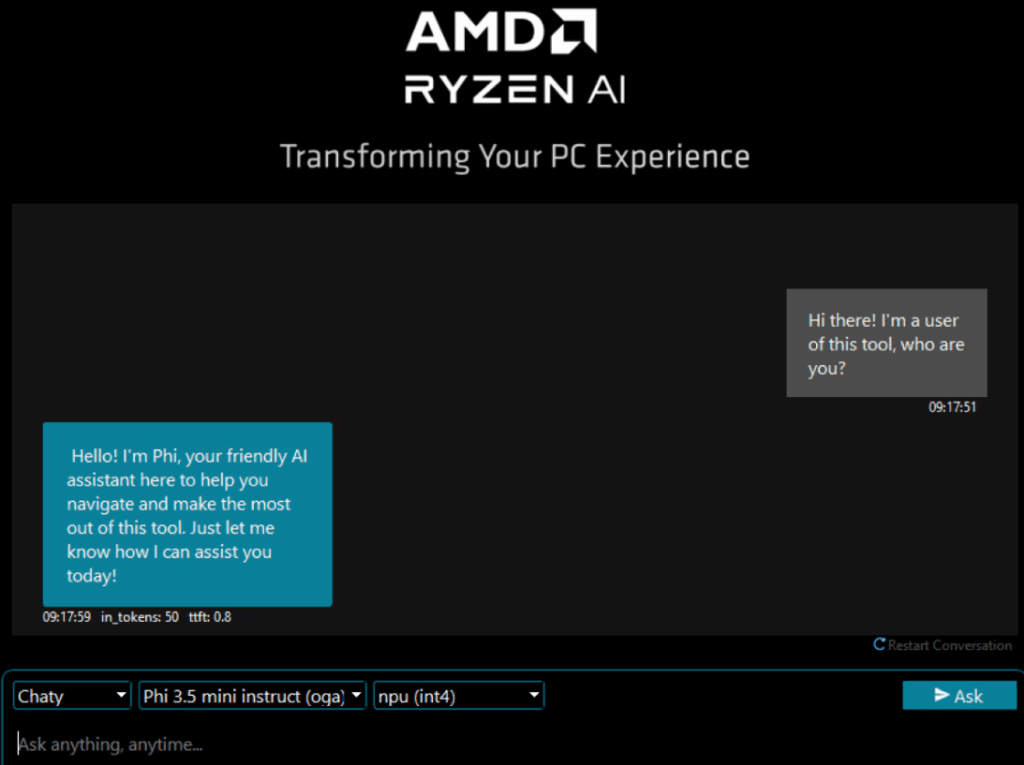
Источник: amd.com
Первое впечатление: установка проходит быстрее аналогов благодаря предварительно собранным пакетам, но выбор между установщиками требует понимания архитектуры вашего оборудования. Интерфейс кажется сбалансированным — достаточно настроек для тонкой конфигурации, но без перегруженности Text Generation Web UI. Интеграция с Ryzen AI ощущается в скорости отклика — модели запускаются на 15-20% быстрее по сравнению с универсальными решениями.
Выбор установщика
Доступны два варианта установки: Mainstream для любых Windows-систем и Hybrid для оборудования с Ryzen AI. Первый вариант работает на стандартных CPU через ONNX Runtime, второй задействует специализированные AI-ядра процессоров Ryzen 7040/8040 серий и новее. Проверить наличие Ryzen AI можно через диспетчер задач в разделе «Процессоры» — если видите NPU (Neural Processing Unit), выбирайте Hybrid-версию:
# Для систем с Ryzen AI
Gaia_Hybrid_Installer.exe --with-npu-support
# Для стандартных систем
Gaia_Mainstream_Installer.exe --cpu-onlyПосле запуска установщик автоматически определяет конфигурацию оборудования и настраивает параметры для оптимальной производительности. Критерий успешной установки — появление иконки Gaia в системном трее и доступность веб-интерфейса по адресу http://localhost:7865. Если порт занят, система автоматически предложит следующий свободный.
Настройка RAG
Ключевая особенность Gaia — встроенная поддержка RAG через локальную векторную базу данных. После установки необходимо настроить базу документов — система поддерживает PDF, DOCX и TXT форматы с автоматическим разбиением на чанки. Процесс индексации запускается через веб-интерфейс или REST API:
curl -X POST http://localhost:7865/api/rag/index -H "Content-Type: application/json" -d '{
"documents_path": "C:/Gaia/documents",
"chunk_size": 512,
"overlap": 50
}'Скорость индексации зависит от объема документов — на Ryzen AI оборудовании обработка 100 страниц занимает 2-3 минуты. Проверить готовность базы можно запросом к эндпоинту /api/rag/status — система должна вернуть количество проиндексированных документов и размер векторной базы. Если индексация зависла, проверьте кодировку текстовых файлов — UTF-8 работает стабильно, другие кодировки могут вызывать ошибки.
Важный нюанс: при работе с большими коллекциями документов лучше увеличить размер чанков до 1024 токенов — это улучшает качество поиска релевантных фрагментов, но требует больше оперативной памяти. На системах с 16 ГБ ОЗУ оптимальный баланс достигается при chunk_size=768 и overlap=64.
Запуск агентов
Gaia включает четыре предварительно настроенных агента: Simple Prompt Completion для базовых запросов, Chaty для диалоговых сценариев, Clip для работы с текстом и Joker для креативных задач. Переключение между агентами происходит через веб-интерфейс или API — каждый агент имеет уникальные параметры генерации, оптимизированные под свою специализацию:
curl -X POST http://localhost:7865/api/chat -H "Content-Type: application/json" -d '{
"agent": "Chaty",
"message": "Объясни принцип работы RAG",
"use_rag": true
}'При активации RAG-режима агент автоматически ищет релевантные фрагменты в проиндексированных документах перед генерацией ответа. На практике это обеспечивает более точные и фактологически выверенные ответы по сравнению с чистой генерацией. Скорость работы зависит от выбранного агента — Chaty и Simple Prompt Completion работают быстрее, тогда как Joker требует дополнительного времени на креативную обработку.
Система демонстрирует лучшие результаты на оборудовании AMD с Ryzen AI — ускорение на NPU особенно заметно при одновременной работе нескольких агентов или обработке больших документов через RAG. Технология Lemonade SDK от ONNX обеспечивает кроссплатформенную совместимость, но максимальная производительность достигается именно в связке с оборудованием AMD.
Gaia оптимален для пользователей Windows с процессорами Ryzen, которым нужна локальная AI-система с акцентом на работу с документами. Интеграция RAG из коробки и оптимизация под конкретное железо делают его практичным выбором для бизнес-задач. Не стоит выбирать это решение для кроссплатформенных проектов или на оборудовании Intel/NVIDIA — здесь специализированные оптимизации не работают. Однако для владельцев современных ноутбуков и ПК на AMD, особенно с Ryzen AI, Gaia оказывается наиболее сбалансированным решением по соотношению производительности и функциональности.
Chatbot UI: Локальный клон ChatGPT
Chatbot UI — это фронтенд-решение, которое визуально и функционально повторяет интерфейс ChatGPT, но работает с локальными бэкендами вместо облачных API. В отличие от ранее рассмотренных инструментов, фокус здесь смещен на пользовательский опыт — вы получаете знакомый чат-интерфейс, но с полным контролем над данными и возможностью выбора своего бэкенда. После настройки система поддерживает Ollama, LocalAI и LM Studio, что делает ее универсальным клиентом для различных локальных инфраструктур.

Источник: github.com/mckaywrigley/chatbot-ui
Первое впечатление: интерфейс сначала кажется точной копией ChatGPT — те же блоки диалогов, боковая панель с историей, даже анимации генерации. Однако через 10-15 минут использования замечаешь дополнительные функции — настройка цветовой схемы, экспорт диалогов в Markdown, тонкая настройка параметров для каждого провайдера. По сравнению с нативными интерфейсами бэкендов ощущается как переход от инструмента разработчика к готовому продукту для конечного пользователя.
Настройка бэкенда
Процесс начинается с клонирования репозитория и установки зависимостей. Система требует Node.js версии 18+ и использует стандартный рабочий процесс npm:
git clone https://github.com/mckaywrigley/chatbot-ui
cd chatbot-ui
npm installПосле установки пакетов необходимо настроить подключение к бэкенду через переменные окружения. Для Ollama конфигурация самая простая — достаточно указать базовый URL:
export OLLAMA_HOST=http://localhost:11434Для LM Studio или LocalAI потребуется дополнительная настройка в файле .env.local с указанием соответствующих эндпоинтов. Проверить корректность подключения можно запуском dev-сервера — если интерфейс показывает возможность выбора моделей из бэкенда, значит конфигурация работает правильно.
Важный нюанс: при одновременном использовании разных бэкендов могут возникать конфликты CORS — особенно если фронтенд и бэкенд работают на разных портах. В таких случаях помогает настройка прокси через vite.config.js или запуск всех компонентов на одном домене. Если модели не загружаются, проверьте что сервер бэкенда запущен и доступен по указанному адресу.
Запуск интерфейса
Базовый запуск выполняется через стандартный npm-скрипт, который инициализирует dev-сервер на порту 3000:
npm run devПосле успешного запуска интерфейс доступен по адресу http://localhost:3000. Критерий правильной работы — возможность выбора моделей из подключенного бэкенда и генерация связных ответов на тестовые запросы. Первая загрузка может занимать 30-60 секунд — система инициализирует подключение к бэкенду и загружает список доступных моделей.
Для продакшен-использования рекомендуется сборка статической версии с последующим развертыванием на любом веб-сервере:
npm run build
npm run startСобранная версия работает значительно быстрее и потребляет меньше ресурсов, но требует предварительной настройки всех переменных окружения. На практике разница в скорости загрузки страницы в 2-3 раза в пользу собранной версии.
Интерфейс поддерживает все основные функции оригинального ChatGPT — продолжение диалогов, переименование чатов, ветвление обсуждений. Дополнительные возможности включают настройку системного промпта для каждой модели, установку температуры и максимальной длины ответа прямо в интерфейсе, экспорт отдельных сообщений или целых диалогов. Интеграция с бэкендами происходит практически бесшовно — переключение между Ollama и LM Studio занимает секунды, все настройки автоматически применяются к выбранному провайдеру.
Chatbot UI оптимален для пользователей, ценящих удобную среду взаимодействия, но имеющих требования к конфиденциальности данных. Система показывает лучшие результаты при работе с Ollama для простых чат-задач и LM Studio для сложных сценариев с тонкой настройкой параметров. Это решение не стоит выбирать как самостоятельный продукт — без предварительно настроенных бэкендов это просто пустой интерфейс. Однако в связке с любым из ранее рассмотренных инструментов он обеспечивает опыт, наиболее близкий к ChatGPT с полным сохранением данных на локальном оборудовании.
Сравнительный анализ и рекомендации
После детального изучения десяти локальных альтернатив ChatGPT становится очевидной специализация каждого решения. Ключевые параметры сравнения включают простоту установки, поддержку моделей, функциональность и требования к оборудованию — эти критерии определяют практическую применимость инструментов в разных сценариях.
Сравнительная таблица по основным характеристикам показывает четкое разделение ниш:
| Инструмент | Сложность установки | Поддержка моделей | Ключевая функция | Минимальные требования |
|---|---|---|---|---|
| GPT4All | Низкая | Встроенный каталог | Простой чат | 8 ГБ ОЗУ |
| Ollama | Средняя | Расширенный каталог | Сервер + API | 8 ГБ ОЗУ |
| LM Studio | Низкая | Встроенный каталог | Графический интерфейс | 8 ГБ ОЗУ |
| LocalAI | Высокая | Ручная настройка | OpenAI API совместимость | 16 ГБ ОЗУ + Docker |
| Text Generation Web UI | Высокая | Ручная загрузка | Расширенные настройки | 16 ГБ ОЗУ |
| PrivateGPT | Средняя | Ограниченный набор | RAG система | 16 ГБ ОЗУ |
| Jan | Средняя | Внешние бэкенды | Минималистичный интерфейс | 8 ГБ ОЗУ |
| KoboldAI | Средняя | Специализированные | Творческое письмо | 12 ГБ ОЗУ |
| Gaia | Низкая | Оптимизированные | Интеграция с AMD | 16 ГБ ОЗУ + Ryzen AI |
| Chatbot UI | Средняя | Внешние бэкенды | Интерфейс ChatGPT | 8 ГБ ОЗУ |
На практике простота установки обратно пропорциональна гибкости настройки — готовые решения вроде GPT4All запускаются за минуты, но не позволяют тонко управлять параметрами генерации. Серверные варианты типа Ollama требуют работы с командной строкой, но обеспечивают стабильную работу в фоне и интеграцию через API.
Рекомендации по выбору
Для новичков и не технических пользователей оптимальным выбором становится GPT4All — установка занимает минуты, интерфейс интуитивен, а встроенный каталог моделей избавляет от ручного поиска файлов. Система стабильно работает даже на скромном оборудовании с 8 ГБ ОЗУ, хотя на сложных запросах может ощущаться ограниченность моделей. LM Studio предлагает схожую простоту установки, но с расширенными возможностями за счет графического интерфейса и встроенного API-сервера.
Разработчикам и техническим специалистам стоит обратить внимание на Ollama и LocalAI. Первый обеспечивает быстрый старт с минимальной конфигурацией, но покрывает большинство потребностей через REST API. Второй требует больше усилий на установку через Docker, но предлагает полную совместимость с OpenAI API — это критично при миграции существующих проектов с облачных сервисов. Для интеграции в продакшен-среды LocalAI оказывается надежнее благодаря контейнеризации и изоляции зависимостей.
Для работы с документами PrivateGPT остается единственным полнофункциональным решением с поддержкой RAG из коробки. Система демонстрирует лучшие результаты с технической и юридической документацией, где важна точность цитирования источников. Альтернативой может служить Gaia с его встроенными агентами для анализа документов, но это решение оптимизировано specifically под оборудование AMD.
Творческим профессионалам — писателям, сценаристам, копирайтерам — лучше подойдет KoboldAI с его специализацией на художественных текстах. Расширенные настройки генерации, управление персонажами и поддержка сетевого режима Horde делают его практичным инструментом для создания сложных нарративов. Text Generation Web UI предлагает схожие возможности, но требует более глубокого погружения в технические детали.
Аппаратные требования становятся решающим фактором при выборе между решениями. Минимальная конфигурация — 8 ГБ ОЗУ — подходит только для базовых моделей вроде Mistral 7B. Для комфортной работы с 13-миллиардными моделями рекомендуется 16 ГБ оперативной памяти, а для самых продвинутых вариантов типа Llama 3 70B потребуется 32 ГБ и более. Наличие GPU с поддержкой CUDA (NVIDIA) или ROCm (AMD) ускоряет генерацию в 3-5 раз — разница особенно заметна при работе с длинными контекстами.
Практический вывод: выбор конкретного инструмента зависит от комбинации трех факторов — технической подготовки пользователя, специфики задач и доступного оборудования.
Для разового использования или знакомства с технологией достаточно GPT4All или LM Studio. Для коммерческих проектов с требованиями к конфиденциальности лучше подходят Ollama или LocalAI. Специализированные задачи вроде анализа документов или творческого письма требуют соответствующих профильных решений. В любом случае, начинать стоит с простых вариантов — большинство инструментов позволяют экспортировать настройки и мигрировать на более продвинутые платформы по мере роста потребностей.



Оставить комментарий